Developer Guide
Key Concepts
Before diving into SWIRL's architecture, here are the core components referenced throughout this guide:
- SearchProvider - a JSON configuration that defines a searchable data source, including its connector type, URL, credentials, and field mappings.
- Connector - a Python module that handles communication with a specific type of data source (REST API, database, vector store, etc.).
- Processor - a Python module that transforms queries (QueryProcessor) or results (ResultProcessor) at various stages of the search pipeline.
- Mixer - a module that combines and re-ranks results from multiple SearchProviders into a unified result set.
- Query Transform - a reusable rule that modifies search queries, such as expanding synonyms or rewriting terms.
- Reader LLM - a non-generative language model (typically spaCy) used for computing relevancy embeddings and re-ranking results, distinct from the generative LLM used for RAG.
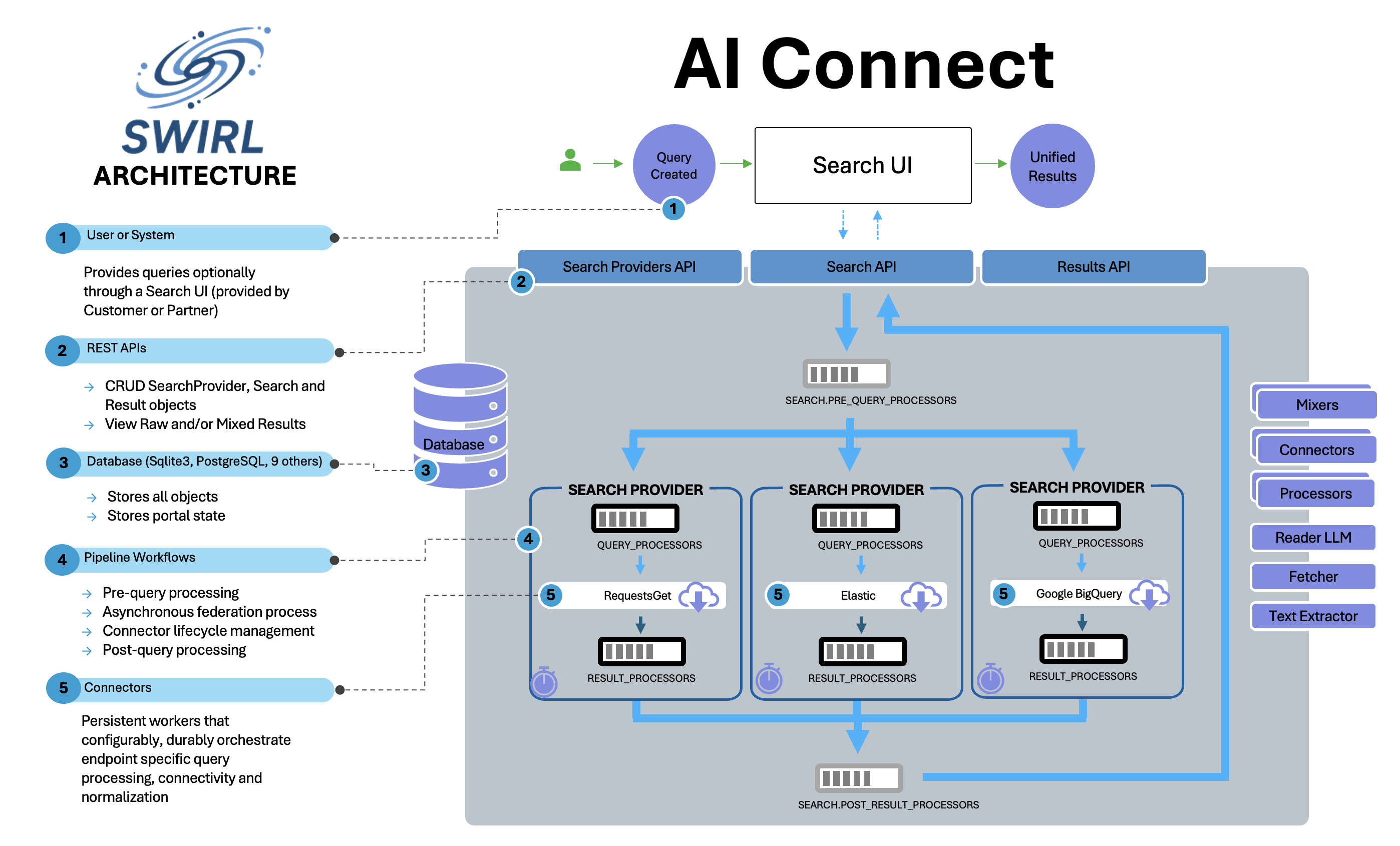
Architecture
SWIRL AI Search
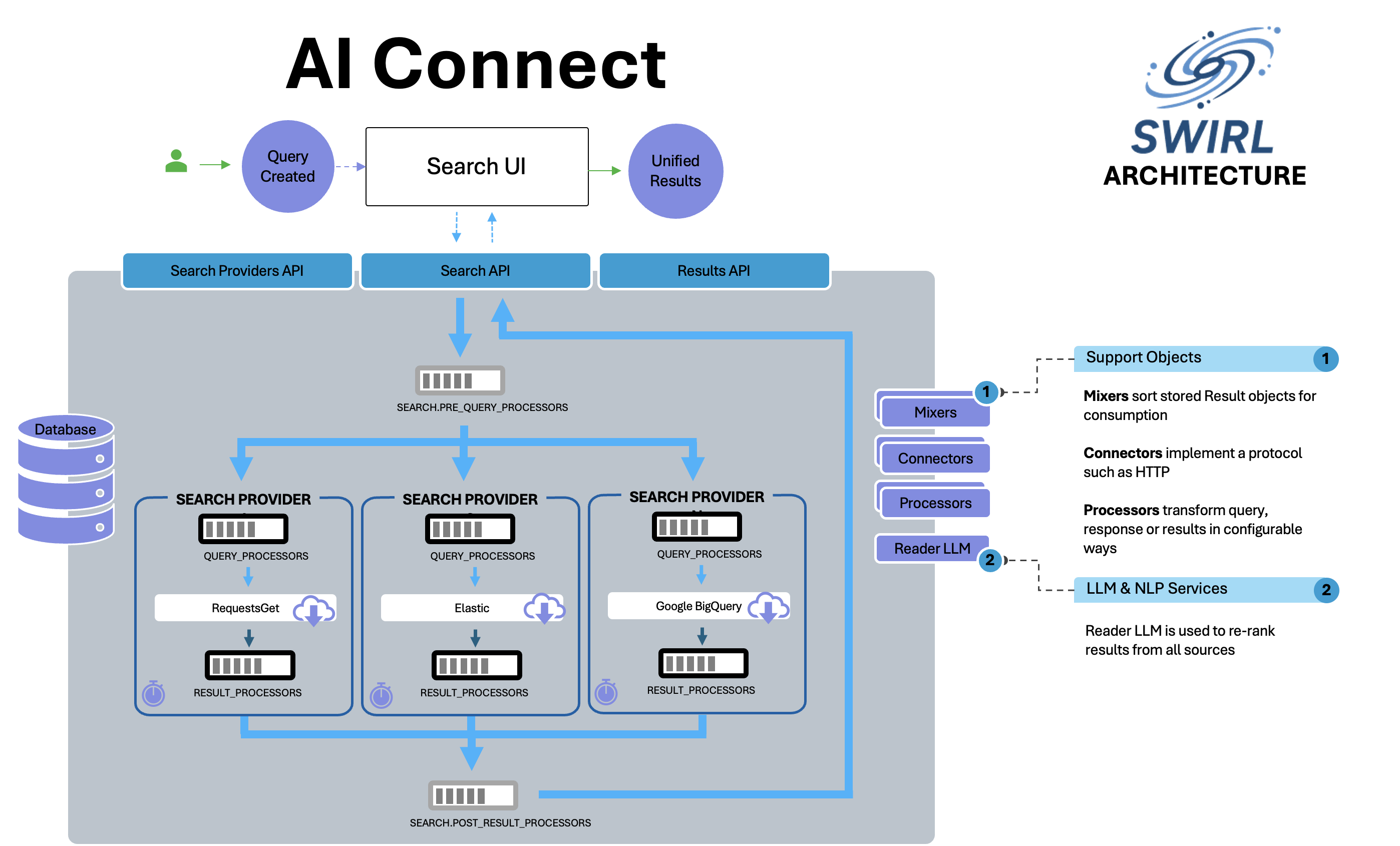
SWIRL RAG Architecture
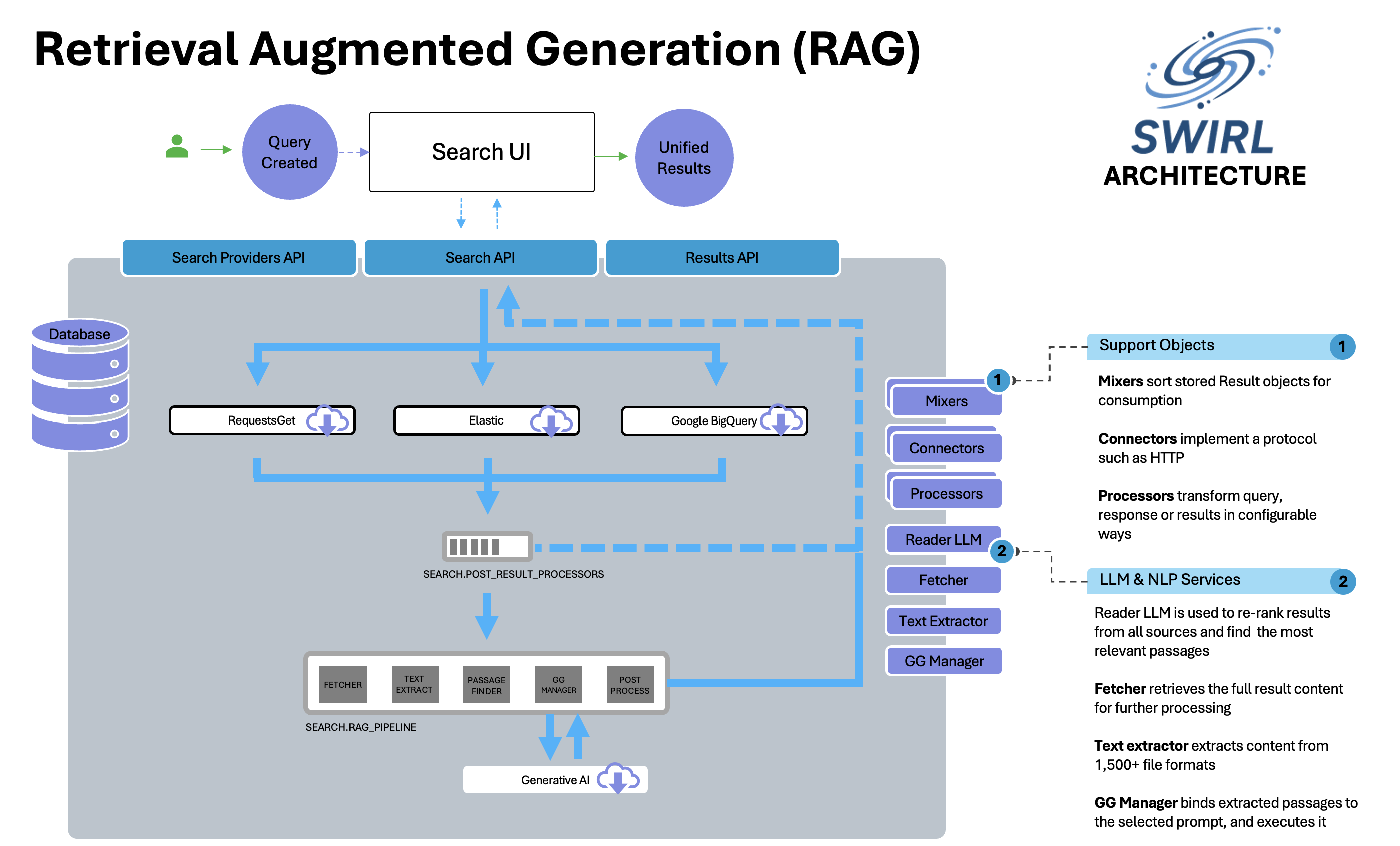
SWIRL AI Search Assistant
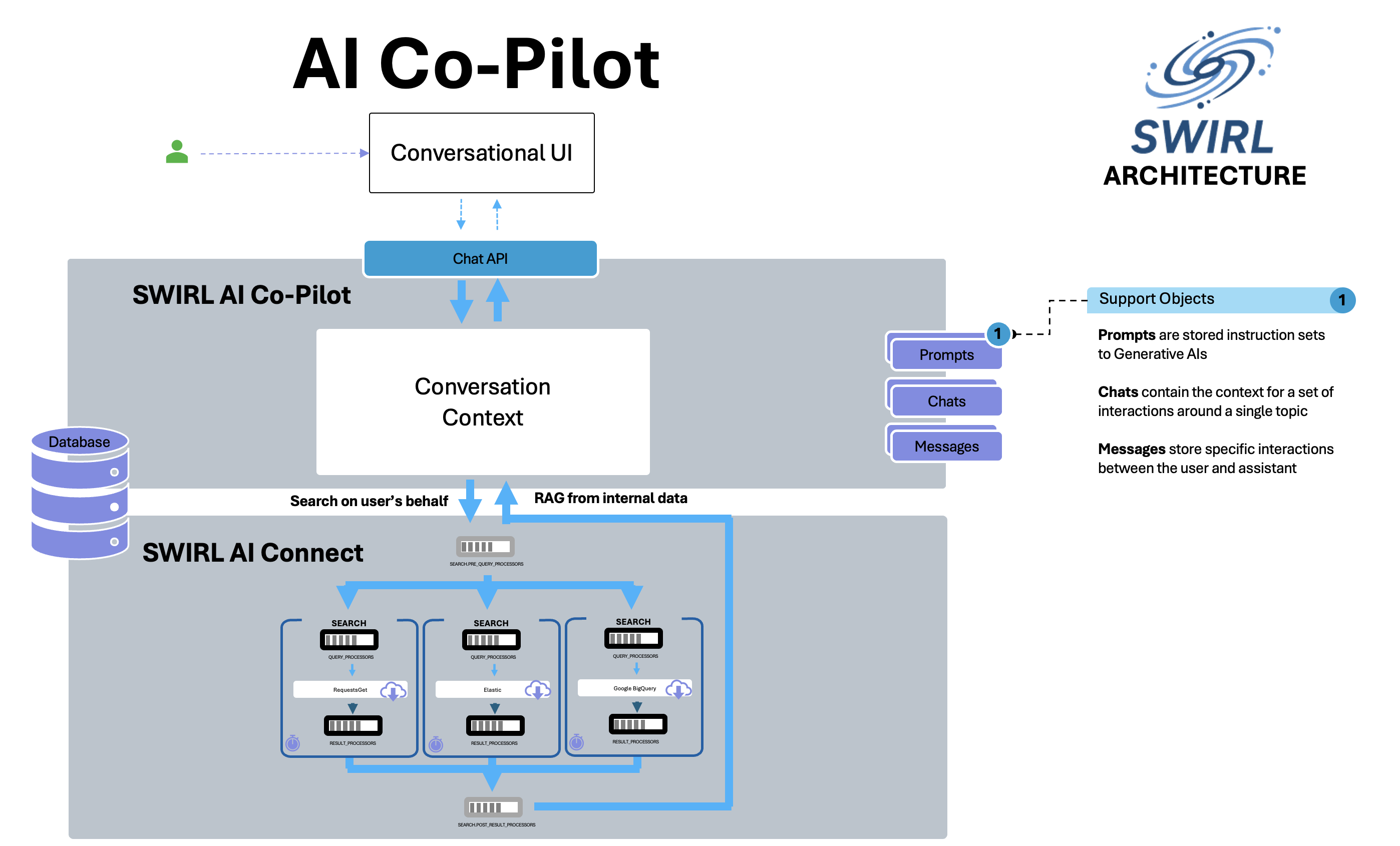
Workflow
-
Creating a Search
A new
Searchobject is created at the/swirl/search/endpoint.- This calls the
createmethod inswirl/views.py. - SWIRL responds with the
idof the newly created search. - The federation process is then managed by
swirl/search.py.
- This calls the
-
Executing the Search
swirl/search.pyperforms:- Pre-query processing using
Search.pre_query_processors. - Federation by creating a
federate_taskfor each SearchProvider.
- Pre-query processing using
-
Waiting for Results
- SWIRL waits for all tasks to complete or until
settings.SWIRL_TIMEOUTis reached. -
Meanwhile, each
federate_task:- Creates a Connector.
- Processes the query using
Search.query_processors. - Builds and validates the query (
url,query_template,query_mappings). - Sends the query to the SearchProvider.
- Normalizes and processes results (
Search.result_processors). - Saves results in the database.
- SWIRL waits for all tasks to complete or until
-
Post-Processing and Relevancy Ranking
Once results are available (or the timeout occurs):
search.pyinvokesSearch.post_result_processors.- Relevancy ranking and duplicate detection are applied.
- The
Search.statusis updated toFULL_RESULTS_READYorPARTIAL_RESULTS_READY.
-
Retrieving Results
To retrieve results, use
/swirl/results:- All result objects are listed.
- Individual results can be retrieved using their
id. - Adding
search_idgroups results using the Result Mixer.
-
Continuous Updates with
subscribeIf
Search.subscribe = true:- SWIRL will periodically re-run the search.
- The sort order is set to
date, fetching newer results. - Merging and de-duplication ensure no duplicate results.
To retrieve only new results, use Search.new_results_url or select a NewItem Mixer.
API Examples
All SWIRL API endpoints require authentication. The examples below use HTTP Basic Authentication - the simplest approach for scripts and command-line tools. Replace admin:password with your actual credentials.
SWIRL's API is mounted under two prefixes - /swirl/... and /api/swirl/... - that serve the same endpoints; the examples below use /swirl/, and either prefix works.
Tip: In interactive shells, quote the password with single quotes to prevent expansion of special characters like ! (e.g. -u 'admin:my!pass'). In Python, prefer loading credentials from environment variables over hardcoding them.
Authentication
SWIRL Community accepts two authentication schemes on every API endpoint: HTTP Basic (simple, suitable for scripts) and DRF Token (preferred for long-running integrations, since the token can be revoked without changing the user's password).
curl - Basic auth:
## Every request passes Basic Auth credentials via -u
curl -u admin:password http://localhost:8000/swirl/searchproviders/
curl - Token auth (COMMUNITY):
## Generate a token from /admin/authtoken/tokenproxy/, then pass it via Authorization header
curl -H "Authorization: Token your-swirl-api-token" http://localhost:8000/swirl/searchproviders/
Python - Basic auth:
import requests
BASE_URL = "http://localhost:8000"
session = requests.Session()
session.auth = ("admin", "password") # HTTP Basic Auth applied to every request
## Sanity check
response = session.get(f"{BASE_URL}/swirl/searchproviders/")
response.raise_for_status()
Python - Token auth (COMMUNITY):
import os, requests
session = requests.Session()
session.headers.update({
"Authorization": f"Token {os.environ['SWIRL_TOKEN']}",
})
For the full schema - including request/response examples for every endpoint - see the live Swagger / OpenAPI docs at http://localhost:8000/swirl/api/docs/.
Running a Search
curl - asynchronous (returns search ID immediately):
## Create a search and get the search ID
curl -u admin:password -X POST http://localhost:8000/swirl/search/ \
-H "Content-Type: application/json" \
-d '{"query_string": "artificial intelligence"}'
## Poll for results (replace 1 with your search ID)
curl -u admin:password "http://localhost:8000/swirl/results/?search_id=1"
curl - synchronous (waits for results):
## Run a search and get results in one call
curl -u admin:password "http://localhost:8000/swirl/search/?qs=artificial+intelligence"
Python - synchronous search:
## Synchronous search - returns results directly
response = session.get(f"{BASE_URL}/swirl/search/", params={
"qs": "artificial intelligence"
})
results = response.json()
## Access the mixed results
for result in results.get("results", []):
print(f"{result['swirl_rank']}. {result['title']}")
print(f" Score: {result.get('swirl_score', 'N/A')}")
print(f" Source: {result['searchprovider']}")
print(f" URL: {result['url']}")
print()
Python - asynchronous search with polling:
import time
## Create the search
response = session.post(f"{BASE_URL}/swirl/search/", json={
"query_string": "artificial intelligence",
"results_requested": 20
})
search = response.json()
search_id = search["id"]
print(f"Search created: ID {search_id}, status: {search['status']}")
## Poll until results are ready
while True:
response = session.get(f"{BASE_URL}/swirl/search/{search_id}/")
search = response.json()
if search["status"] in ("FULL_RESULTS_READY", "PARTIAL_RESULTS_READY"):
break
time.sleep(0.5)
## Retrieve mixed results
response = session.get(f"{BASE_URL}/swirl/results/", params={
"search_id": search_id,
"result_mixer": "RelevancyMixer"
})
results = response.json()
print(f"Got {len(results.get('results', []))} results")
Targeting Specific SearchProviders
curl:
## Search only specific providers by name
curl -u admin:password -X POST http://localhost:8000/swirl/search/ \
-H "Content-Type: application/json" \
-d '{
"query_string": "machine learning",
"searchprovider_list": ["Arxiv.org", "European PMC"]
}'
Python:
response = session.post(f"{BASE_URL}/swirl/search/", json={
"query_string": "machine learning",
"searchprovider_list": ["Arxiv.org", "European PMC"]
})
Search with RAG
curl - synchronous RAG search:
## Run a search with RAG in one call
curl -u admin:password "http://localhost:8000/swirl/search/?qs=what+is+retrieval+augmented+generation&rag=true"
curl - RAG with timeout override:
curl -u admin:password "http://localhost:8000/swirl/search/?qs=summarize+recent+AI+advances&rag=true&rag_timeout=120"
Python - RAG search:
## Synchronous RAG search
response = session.get(f"{BASE_URL}/swirl/search/", params={
"qs": "what is retrieval augmented generation",
"rag": "true"
})
rag_results = response.json()
## The AI-generated summary is returned as a result row whose author is
## the SWIRL RAG processor. Pull it out of the results list.
RAG_AUTHOR = "SWIRL RAG AI Results Processor"
ai_summary = next(
(r for r in rag_results.get("results", []) if r.get("author") == RAG_AUTHOR),
None,
)
if ai_summary:
print("AI Summary:", ai_summary.get("body", "(empty)"))
## Citations are the remaining rows in the same results list
for result in rag_results.get("results", []):
if result.get("author") == RAG_AUTHOR:
continue
print(f" - {result['title']} ({result['url']})")
Enterprise RAG Search API
In SWIRL Enterprise, /swirl/rag-search/ generates an AI summary over an existing search - it is not a combined search+RAG endpoint. Call it in two steps: create the search first, then POST its search_id (and optionally a result_list of result row numbers to summarize) to /swirl/rag-search/. Omit result_list to summarize all results for that search.
curl:
## 1. Create a search and note the id from the response
curl -u admin:password -X POST http://localhost:8000/swirl/search/ \
-H "Content-Type: application/json" \
-d '{"query_string": "summarize key findings on climate change",
"searchprovider_list": ["Google News", "Arxiv.org"]}'
## → {"id": 42, ...}
## 2. Generate a RAG summary over that search
curl -u admin:password -X POST http://localhost:8000/swirl/rag-search/ \
-H "Content-Type: application/json" \
-d '{"search_id": 42, "result_list": [1, 2, 3]}'
Python:
## Step 1 - create the search
r = session.post(f"{BASE_URL}/swirl/search/", json={
"query_string": "summarize key findings on climate change",
"searchprovider_list": ["Google News", "Arxiv.org"],
})
search_id = r.json()["id"]
## Step 2 - summarize selected result rows (or omit result_list for all)
r = session.post(f"{BASE_URL}/swirl/rag-search/", json={
"search_id": search_id,
"result_list": [1, 2, 3],
})
Retrieving Results with Different Mixers
curl:
## Default relevancy-ranked results
curl -u admin:password "http://localhost:8000/swirl/results/?search_id=1"
## Date-sorted results
curl -u admin:password "http://localhost:8000/swirl/results/?search_id=1&result_mixer=DateMixer"
## Round-robin across sources
curl -u admin:password "http://localhost:8000/swirl/results/?search_id=1&result_mixer=Stack2Mixer"
## Paginate results (10 per page)
curl -u admin:password "http://localhost:8000/swirl/results/?search_id=1&page=2"
Python:
## Get results with a specific mixer
response = session.get(f"{BASE_URL}/swirl/results/", params={
"search_id": search_id,
"result_mixer": "DateMixer"
})
date_sorted = response.json()
## Paginate through results
page = 1
while True:
response = session.get(f"{BASE_URL}/swirl/results/", params={
"search_id": search_id,
"page": page
})
data = response.json()
results = data.get("results", [])
if not results:
break
for r in results:
print(f" {r['swirl_rank']}. {r['title']}")
page += 1
Listing SearchProviders
curl:
## List all active SearchProviders
curl -u admin:password http://localhost:8000/swirl/searchproviders/
Python:
response = session.get(f"{BASE_URL}/swirl/searchproviders/")
providers = response.json()
for sp in providers:
status = "active" if sp["active"] else "inactive"
default = " (default)" if sp["default"] else ""
print(f" [{sp['id']}] {sp['name']} - {sp['connector']} - {status}{default}")
Listing AIProviders (COMMUNITY)
curl:
## List all configured AIProviders
curl -u admin:password http://localhost:8000/swirl/aiproviders/
Python:
response = session.get(f"{BASE_URL}/swirl/aiproviders/")
aips = response.json()
for aip in aips:
roles = ",".join(aip.get("config", {}).get("roles", [])) or "-"
print(f" [{aip['id']}] {aip['name']} - {aip['model']} - roles={roles}")
Activating an AIProvider for RAG via API:
curl -u admin:password -X PATCH http://localhost:8000/swirl/aiproviders/1/ \
-H "Content-Type: application/json" \
-d '{"active": true, "api_key": "sk-..."}'
How To...
Work with JSON Endpoints
When using a browser to interact with SWIRL API endpoints (such as those in this guide), disable prefetching to prevent accidental creation of multiple objects via ?q= and ?qs= parameters.
Create a Search Object via API
- Navigate to: http://localhost:8000/swirl/search/
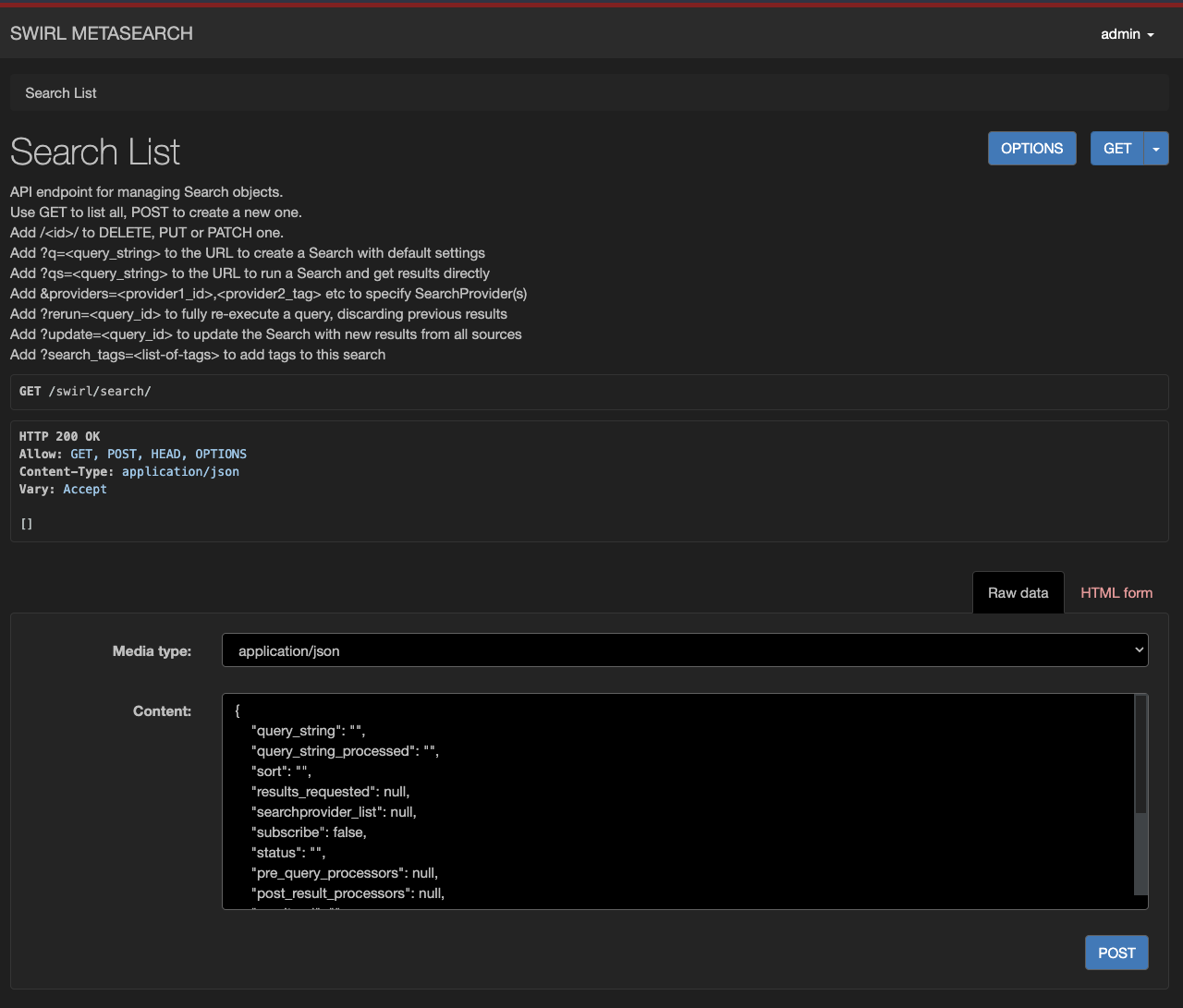
- Scroll to the form at the bottom of the page.
- Switch to Raw data mode and clear any pre-filled content.
- Copy and paste an example Search object.
- Click POST.
SWIRL responds with the newly created Search object, including its id:
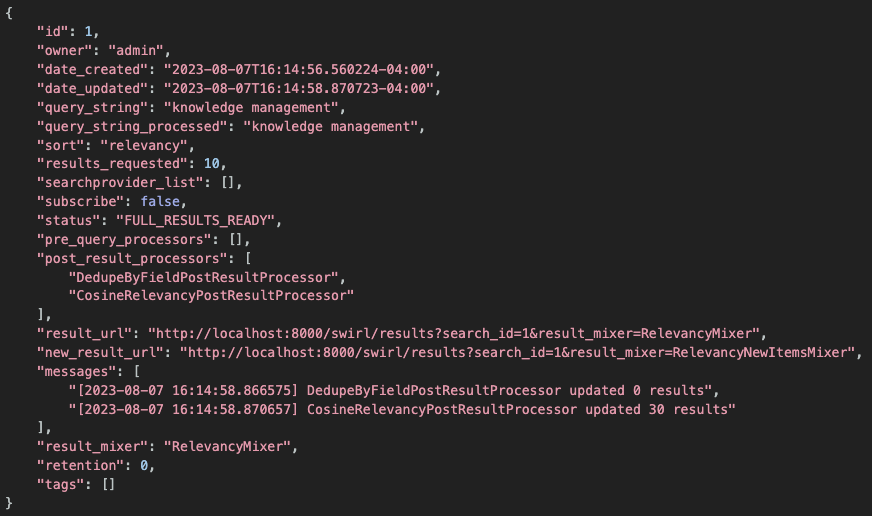
Save the id value - it is required for retrieving ranked results.
Create a Search Object with the q= URL Parameter
To create a Search object with only a query_string (and default settings), append ?q=your-query-string to the API URL.
Example:
http://localhost:8000/swirl/search?q=knowledge+management
After a few seconds, SWIRL redirects to the fully mixed results page:
{
"messages": [
"SWIRL AI SEARCH 5.0.0",
"[2026-05-20 11:38:04.559113] Retrieved 10 of 100 results from: News - Google News",
"[2026-05-20 11:38:04.974641] Retrieved 10 of 5187 results from: Articles - EuropePMC",
"[2026-05-20 11:38:05.507881] Retrieved 10 of 1449 results from: Web - Internet Archive",
"[2026-05-20 11:44:25.983136] Results ordered by: RelevancyMixer"
],
"info": {
"results": {
"found_total": 6727,
"retrieved_total": 30,
"retrieved": 10,
"federation_time": 10.8,
"result_blocks": [
"ai_summary"
],
"next_page": "http://localhost:8000/swirl/results/?search_id=9&page=2"
},
"Web - Internet Archive": {
"found": 1449,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=4",
"query_string_to_provider": "cybersecurity policy",
"search_time": 3.6
},
"Articles - EuropePMC": {
"found": 5187,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=5",
"query_string_to_provider": "cybersecurity policy",
"search_time": 3.2
},
"News - Google News": {
"found": 100,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=2",
"query_string_to_provider": "cybersecurity policy",
"search_time": 2.0
}
},
"results": [
{
"swirl_rank": 1,
"swirl_score": 24911.43237469431,
"searchprovider": "News - Google News",
"searchprovider_rank": 5,
"title": "Maryland unveils statewide zero-trust <em>cybersecurity</em> <em>policy</em> - StateScoop",
"url": "https://news.google.com/rss/articles/CBMijgFBVV95cUxOR2VDaEJaU1ZVNzg4Xzc3SGZkTkV3MEFrblFZTExJcXh1OWN...",
"body": "Maryland unveils statewide zero-trust <em>cybersecurity</em> <em>policy</em> StateScoop...",
"date_published": "2026-02-24 08:00:00+00:00",
"author": "StateScoop",
"swirl_id": 5
},
{
"swirl_rank": 9,
"swirl_score": 5750.152160674617,
"searchprovider": "Articles - EuropePMC",
"searchprovider_rank": 1,
"title": "<em>Cybersecurity</em> <em>policy</em> framework requirements for the establishment of highly interoperable and intercon",
"url": "https://europepmc.org/article/MED/38784226",
"body": "This paper examines <em>cybersecurity</em> <em>policy</em> framework requirements for establishing highly interoperable and interconnected health data spaces, w...",
"date_published": "2024-01-01 00:00:00",
"author": "Luidold C, Jungbauer C.",
"swirl_id": 11
}
],
"ai_summary": []
}
Limitations of q=:
- The query must be URL-encoded (e.g., spaces →
+). Use a free URL encoder for assistance. - All active and default SearchProviders are queried.
- Limited error handling - if no results appear, inspect the Search object:
http://localhost:8000/swirl/search/<your-search-id>
Specify SearchProviders with providers= URL Parameter
Use the providers= parameter to specify a single SearchProvider or a list of Tags.
Example: Querying a single provider
http://localhost:8000/swirl/search/?q=knowledge+management&providers=maritime
Example: Querying multiple providers by Tag
http://localhost:8000/swirl/search/?q=knowledge+management&providers=maritime,news
Get Synchronous Results with qs= URL Parameter
The qs= parameter functions like q=, except that it immediately returns the first page of results instead of redirecting.
Example:
http://localhost:8000/swirl/search?qs=knowledge+management
qs= Supports:
- Filtering by SearchProviders using providers=.
- Using custom Mixers via result_mixer=.
- Enabling RAG processing in a single call:
?qs=metasearch&rag=true
Overriding RAG Timeout
You can override the default AI Summary timeout:
Example:
http://localhost:8000/galaxy/?q=gig%20economics&rag=true&rag_timeout=90
rag_timeout is specified in seconds.
Paging with qs=
&page= is NOT supported with qs=.
Instead, use the next_page property from the info.results structure:
"results": {
"retrieved_total": 30,
"retrieved": 10,
"federation_time": 2.2,
"result_blocks": ["ai_summary"],
"next_page": "http://localhost:8000/swirl/results/?search_id=2&page=2"
}
Request Date-Sorted Results
If "sort": "date" is specified in a Search object, SWIRL will request results in chronological order from providers that support date sorting.
However, by default, SWIRL still applies relevancy ranking, ensuring a mix of the most recent and most relevant results.
{
"messages": [
"SWIRL AI SEARCH 5.0.0",
"[2026-05-20 11:38:04.559113] Retrieved 10 of 100 results from: News - Google News",
"[2026-05-20 11:38:04.974641] Retrieved 10 of 5187 results from: Articles - EuropePMC",
"[2026-05-20 11:38:05.507881] Retrieved 10 of 1449 results from: Web - Internet Archive",
"[2026-05-20 11:58:11.988764] Results ordered by: DateMixer"
],
"info": {
"results": {
"found_total": 6727,
"retrieved_total": 23,
"retrieved": 10,
"federation_time": 10.8,
"result_blocks": [
"ai_summary"
],
"next_page": "http://localhost:8000/swirl/results/?search_id=9&result_mixer=DateMixer&page=2"
},
"Web - Internet Archive": {
"found": 1449,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=4",
"search_time": 3.6
},
"Articles - EuropePMC": {
"found": 5187,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=5",
"search_time": 3.2
},
"News - Google News": {
"found": 100,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=2",
"search_time": 2.0
}
},
"results": [
{
"swirl_rank": 1,
"swirl_score": 7789.906596983473,
"searchprovider": "News - Google News",
"title": "<em>Cybersecurity</em> Will Swallow Digital <em>Policy</em> in the AI Age - Tech <em>Policy</em> Pre",
"url": "https://news.google.com/rss/articles/CBMihwFBVV95cUxNTWpPbU9lLW5tMGV4NmNxYjhtV1l...",
"date_published": "2026-05-18 15:34:16+00:00",
"date_published_display": "",
"swirl_id": 1
},
{
"swirl_rank": 4,
"swirl_score": 1402.8175416857446,
"searchprovider": "Web - Internet Archive",
"title": "<em>Cybersecurity</em> challenges in healthcare: mitigating risks in a rapidly evolving digital land",
"url": "https://archive.org/details/10.11591eei.v14i6.9685",
"date_published": "2026-04-16 03:04:26+00:00",
"date_published_display": "",
"swirl_id": 25
}
],
"ai_summary": []
}
Handling Missing Date Information
Some sources do not provide a date_published field.
To address this, use the DateFinderResultProcessor to detect dates from content fields and map them to date_published.
Use an LLM to Rewrite Queries
SWIRL AI Search supports query rewriting using an LLM. To set this up, add the GenAIQueryProcessor to some SearchProvider.query_processors list.
For details, see: Developer Reference - GenAIQueryProcessor
Adjust swirl_score for Starred Results in Galaxy UI
SWIRL Community Edition
- Configured via "minimumSwirlScore" in static/api/config/default.
- Default: 100. Increase this to reduce starred results.
SWIRL Enterprise Edition
- Configured via "minimumConfidenceScore" in static/api/config/default.
- Default: 0.7. Increase this to reduce the number of starred results and use only highly relevant results.
Handle NOT Queries
If a SearchProvider returns a result containing a NOT-ted term, SWIRL logs a Relevancy Explain message.
Solution
- Verify the SearchProvider supports NOT queries.
- Ensure the correct
NOTquery-mapping is set.
Subscribe to a Search
When "subscribe": true, SWIRL automatically re-runs the search per the Celery-Beats schedule, with sort set to "date" to fetch new results.
Example Search Object with Subscription
{
"id": 10,
"query_string": "electric vehicles NOT tesla",
"sort": "relevancy",
"subscribe": true,
"status": "FULL_RESULTS_READY",
"result_url": "http://localhost:8000/swirl/results?search_id=10&result_mixer=RelevancyMixer",
"new_result_url": "http://localhost:8000/swirl/results?search_id=10&result_mixer=RelevancyNewItemsMixer"
}
Updating a Subscription
Once SWIRL updates the Search, it sets:
"status": "FULL_UPDATE_READY"
New results will have "new": 1. Use new_result_url to retrieve only new results.
Example: Updated Search Object
{
"id": 10,
"query_string": "electric vehicles NOT tesla",
"sort": "date",
"subscribe": true,
"status": "FULL_UPDATE_READY",
"messages": [
"[16:51:43] DedupeByFieldPostResultProcessor deleted 2 results",
"[16:55:02] CosineRelevancyPostResultProcessor updated 58 results",
"[17:00:02] DedupeByFieldPostResultProcessor deleted 30 results"
],
"result_url": "http://localhost:8000/swirl/results?search_id=10&result_mixer=RelevancyMixer",
"new_result_url": "http://localhost:8000/swirl/results?search_id=10&result_mixer=RelevancyNewItemsMixer"
}
The messages field logs federation processing details, while individual Result objects contain source-specific messages.
Viewing Only New Results
Use the NewItems Mixers to retrieve only newly added results.
Detect and Remove Duplicate Results
SWIRL includes two PostResultProcessors for duplicate detection:
| Processor | Description | Notes |
|---|---|---|
| DedupeByFieldPostResultProcessor | Removes duplicates based on exact match of a field. | The field is set in swirl_server/settings.py (SWIRL_DEDUPE_FIELD, default: url). |
| DedupeBySimilarityPostResultProcessor | Detects near-duplicates by similarity of title and body. By default (SWIRL_DEDUPE_GROUP_NOT_DROP=True) near-duplicates are grouped rather than dropped, so the UI can show them as one cluster. |
The similarity threshold is SWIRL_DEDUPE_SIMILARITY_MINIMUM (default 0.95) in settings.py. |
Default Configuration
Both processors are enabled by default in the system-default post-result Pipeline (CosineRelevancyPostResultProcessor → DedupeByFieldPostResultProcessor → DedupeBySimilarityPostResultProcessor → VersionClusteringPostResultProcessor).
To modify this, edit the System Default Post-Result Pipeline in the Django Admin.
Manage Search Objects
To edit a Search, append its id to the /swirl/search/ URL:
Example:
http://localhost:8000/swirl/search/1/
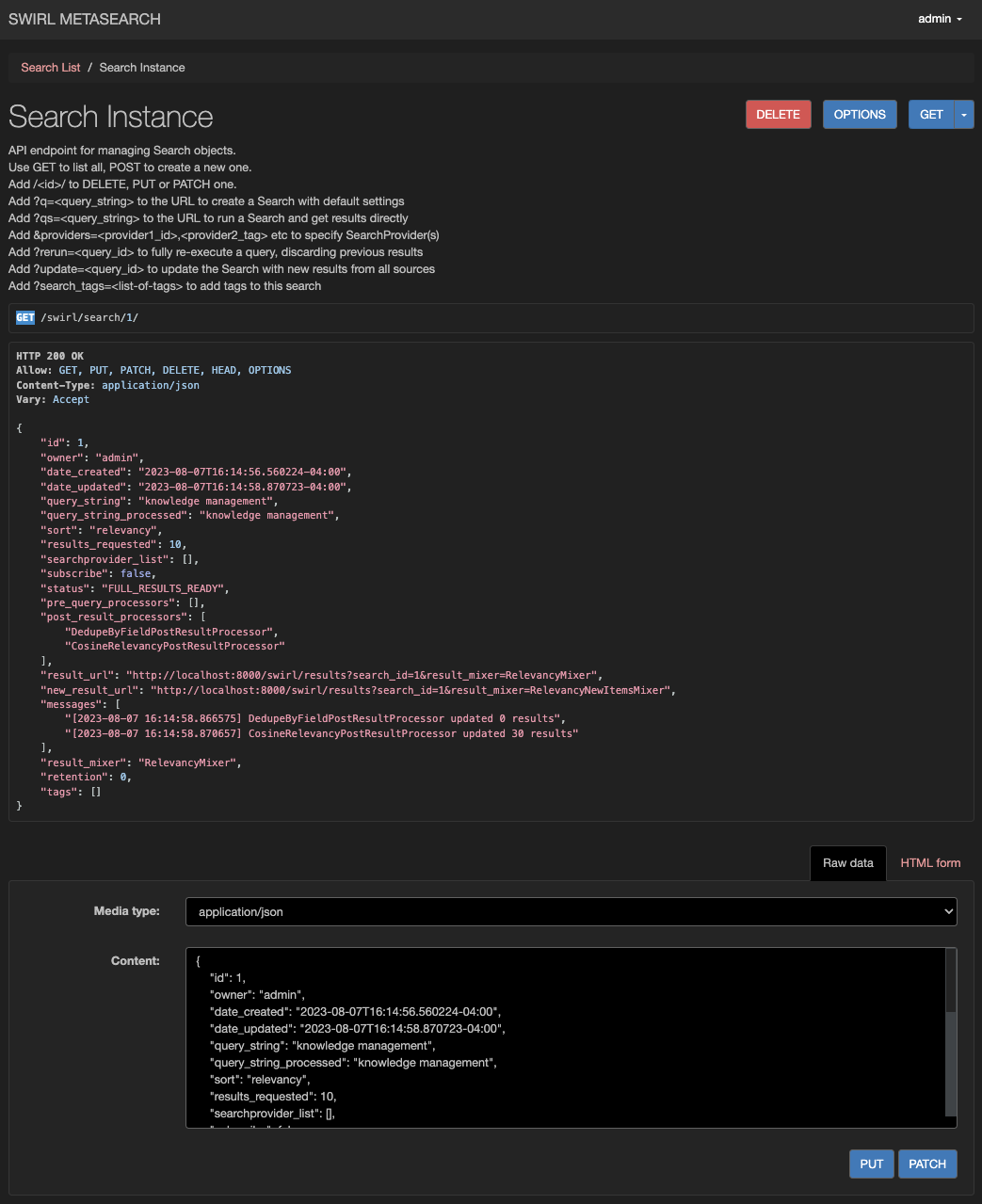
Available Actions:
- DELETE the Search (permanently deletes associated Results).
- Edit the request body and PUT the updated Search.
Deleting a Search also deletes all associated Results immediately.
Re-Run a Search
To discard previous results and re-run a Search, use:
http://localhost:8000/swirl/search?rerun=<search-id>
- This restarts the search from scratch.
- The re-run URL is included in the
info.searchsection of every mixed result response.
Update a Search
To re-run a Search but keep previous results, use:
http://localhost:8000/swirl/search/?update=<search-id>
Behavior:
- Changes
Search.sortto"date"to prioritize new results. - De-duplicates results using the
urlfield. - Updates Search and Result messages as the process runs.
Use RelevancyNewItemsMixer and DateNewItemsMixer to retrieve only new results.
Improve Relevancy for a Single SearchProvider
To filter results where the query string is not in the title, use:
"RequireQueryStringInTitleResultProcessor"
How It Works:
- Install it after MappingResultProcessor in result_processors.
- Removes results that do not contain the query in the title.
When to Use: - Recommended for sources like LinkedIn, which may return related but irrelevant profiles. - Normally, SWIRL ranks these results poorly - this eliminates them entirely.
Find Dates in Body/Title Responses
To detect and extract dates from result content, use:
"DateFinderResultProcessor"
How It Works:
- Finds dates in results that lack a date_published field.
- Copies the detected date into date_published.
Usage:
- Add to SearchProvider.result_processors → Processes results from that provider only.
- Add to Search.post_result_processors → Attempts date detection for all results.
Automatically Map Results Using Profiling
The AutomaticPayloadMapperResultProcessor profiles response data to find the best matches for:
- title
- body
- date_published
When to Use:
- Recommended for SearchProviders with poor or missing result_mappings.
- Allows SWIRL to auto-map relevant fields.
Configuration:
- Install after MappingResultProcessor.
- Leave result_mappings blank.
Visualize Structured Data Results
To organize a columnar response into a structured dataset:
"result_mappings": "DATASET"
Example Output:
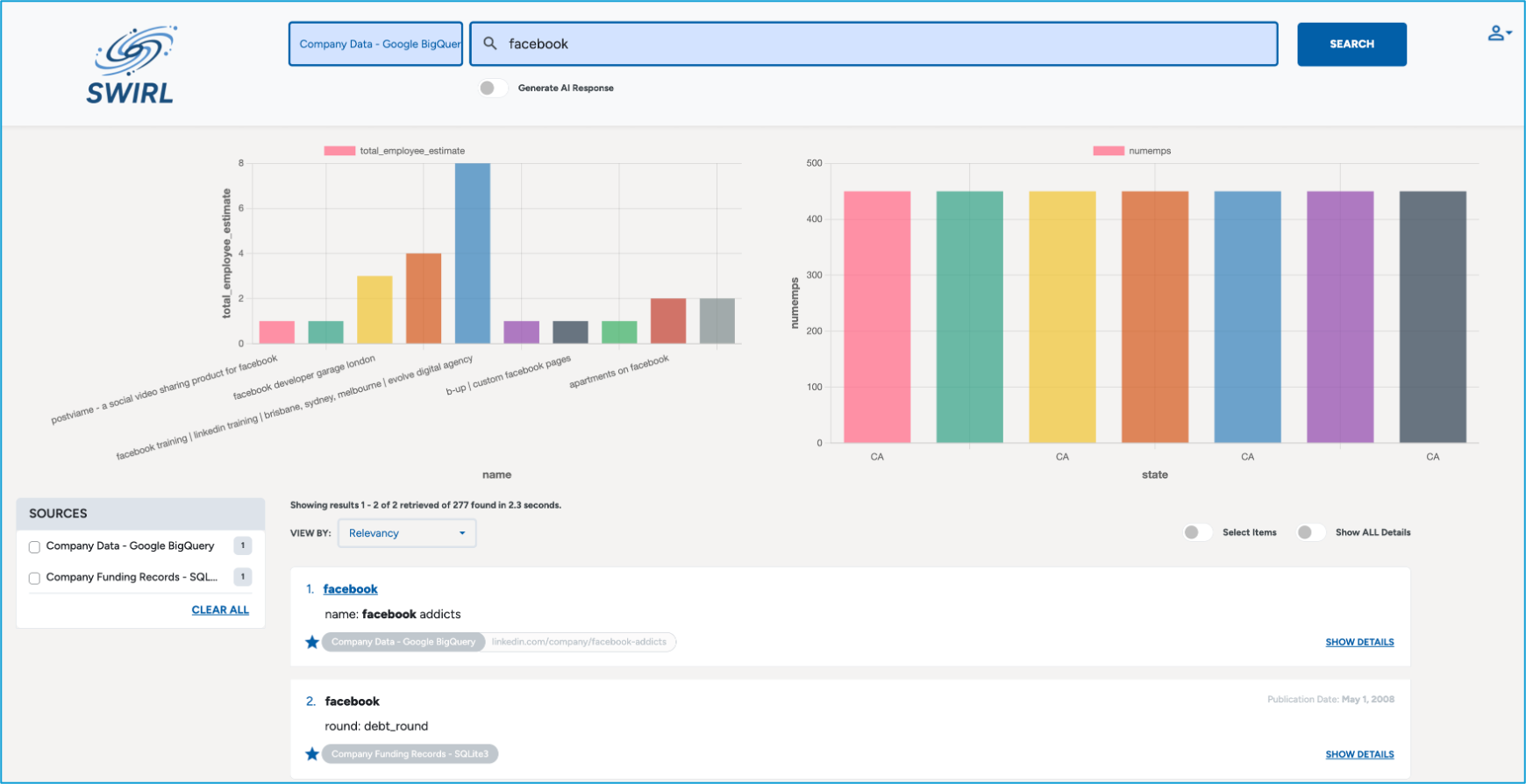
Key Features:
- Fully compatible with result_mappings, including NO_PAYLOAD.
- Automatically generates visualizations using chart.js.
Chart Selection Logic:
- No Numeric Fields → Adds a pseudo-count field → Bar Chart.
- One Numeric Field → Uses Bar Chart.
- Two Numeric Fields → Uses Scatter Chart (if both ranges are positive), otherwise Bar Chart.
- Three+ Numeric Fields → Uses Bubble Chart (if a valid range is found), otherwise Bar Chart.
For assistance, please contact support.
Expire Search Objects
If Search Expiration Service is enabled, users can set Search retention policies.
| Retention Value | Meaning |
|---|---|
| 0 | Retain indefinitely (default) |
| 1 | Retain for 1 hour |
| 2 | Retain for 1 day |
| 3 | Retain for 1 month |
| 4 | Retain for 5 minutes |
Expiration Timing:
- Controlled by
Celery Beat Configuration. - Runs based on
Search Expiration Servicesettings.
Manage Results
To delete or edit a Result, use its id:
Example:
http://localhost:8000/swirl/results/1/
Available Actions: - DELETE the result permanently. - Edit the result and PUT it back.
Deleting a Result does NOT delete the associated Search.
Get Unified Results
Result Mixers organize results from multiple SearchProviders into unified result sets.
Key Features: - Mixers operate on saved results, not live federated data. - Re-running a search updates mixed results dynamically. - Different mixers can be applied on-the-fly via URL parameters.
Retrieve Unified Results
To fetch results for a specific Search, use:
http://localhost:8000/swirl/results?search_id=<search-id>
Example:
http://localhost:8000/swirl/results?search_id=1
SWIRL returns results using the result_mixer specified in the Search object.
{
"messages": [
"SWIRL AI SEARCH 5.0.0",
"[2026-05-20 11:38:04.559113] Retrieved 10 of 100 results from: News - Google News",
"[2026-05-20 11:38:04.974641] Retrieved 10 of 5187 results from: Articles - EuropePMC",
"[2026-05-20 11:38:05.507881] Retrieved 10 of 1449 results from: Web - Internet Archive",
"[2026-05-20 11:44:25.983136] Results ordered by: RelevancyMixer"
],
"info": {
"results": {
"found_total": 6727,
"retrieved_total": 30,
"retrieved": 10,
"federation_time": 10.8,
"result_blocks": [
"ai_summary"
],
"next_page": "http://localhost:8000/swirl/results/?search_id=9&page=2"
},
"Web - Internet Archive": {
"found": 1449,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=4",
"query_string_to_provider": "cybersecurity policy",
"search_time": 3.6
},
"Articles - EuropePMC": {
"found": 5187,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=5",
"query_string_to_provider": "cybersecurity policy",
"search_time": 3.2
},
"News - Google News": {
"found": 100,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=9&provider=2",
"query_string_to_provider": "cybersecurity policy",
"search_time": 2.0
}
},
"results": [
{
"swirl_rank": 1,
"swirl_score": 24911.43237469431,
"searchprovider": "News - Google News",
"searchprovider_rank": 5,
"title": "Maryland unveils statewide zero-trust <em>cybersecurity</em> <em>policy</em> - StateScoop",
"url": "https://news.google.com/rss/articles/CBMijgFBVV95cUxOR2VDaEJaU1ZVNzg4Xzc3SGZkTkV3MEFrblFZTExJcXh1OWN...",
"body": "Maryland unveils statewide zero-trust <em>cybersecurity</em> <em>policy</em> StateScoop...",
"date_published": "2026-02-24 08:00:00+00:00",
"author": "StateScoop",
"swirl_id": 5
},
{
"swirl_rank": 9,
"swirl_score": 5750.152160674617,
"searchprovider": "Articles - EuropePMC",
"searchprovider_rank": 1,
"title": "<em>Cybersecurity</em> <em>policy</em> framework requirements for the establishment of highly interoperable and intercon",
"url": "https://europepmc.org/article/MED/38784226",
"body": "This paper examines <em>cybersecurity</em> <em>policy</em> framework requirements for establishing highly interoperable and interconnected health data spaces, w...",
"date_published": "2024-01-01 00:00:00",
"author": "Luidold C, Jungbauer C.",
"swirl_id": 11
}
],
"ai_summary": []
}
Override Mixer in Real Time
To apply a different mixer, append result_mixer=:
http://localhost:8000/swirl/results?search_id=<search-id>&result_mixer=<mixer-name>
Example:
http://localhost:8000/swirl/results?search_id=1&result_mixer=Stack1Mixer
Page Through Results
By default, SWIRL retrieves at least 10 results per SearchProvider.
To navigate results, append page=:
http://localhost:8000/swirl/results?search_id=<search-id>&page=<page-number>
Example:
http://localhost:8000/swirl/results?search_id=1&page=2
Increase Available Results
To store more results for paging, update results_per_query in the SearchProvider configuration.
- Default:
10 - Recommended for extensive paging:
20,50, or100
Increasing results_per_query requires re-running the search to fetch more results.
Get Search Times
SWIRL reports search execution times per source in the info block:
"info": "Web (Google PSE)": {
"found": 8640,
"retrieved": 10,
"search_time": 2.1
}
The total federation time appears in info.results:
"results": {
"retrieved_total": 50,
"retrieved": 10,
"federation_time": 3.2,
"next_page": "http://localhost:8000/swirl/results/?search_id=507&page=2"
}
Timing Details:
- Units: Seconds (rounded to 0.1 precision).
- Federation Time Includes: Query execution, response processing, post-processing.
- Mixer Processing Time is NOT included in federation time.
Configure Pipelines
Result processing happens in two stages:
SearchProvider.result_processors→ Initial processing.Search.post_result_processors→ Final processing & ranking.
Example: Google PSE Result Processors
"result_processors": [
"MappingResultProcessor",
"DateFinderResultProcessor",
"CosineRelevancyResultProcessor"
]
Modify Default Pipelines
To customize:
- Post Result Processors: Edit the System Default Post-Result Pipeline in the Django Admin. (In SWIRL 5, the Pipeline row - not
getSearchPostResultProcessorsDefault()- is the source of truth for stage ordering.) - Default Mixer: Change the
Search.result_mixerdefault.
result_mixer = models.CharField(max_length=200, default='RelevancyConfidenceMixer', choices=MIXER_CHOICES)
Configure Relevancy Field Weights
To adjust field weights for relevancy scoring, update SWIRL_RELEVANCY_CONFIG in:
swirl_server/settings.py.
Default Weights:
| Field | Weight | Notes |
|---|---|---|
| title | 1.5 |
|
| body | 1.0 |
Base relevancy score |
| author | 1.0 |
Configure Stopwords Language
By default, SWIRL loads English stopwords. To change this:
- Update
SWIRL_DEFAULT_QUERY_LANGUAGEin:
swirl_server/settings.py. - Set it to another NLTK stopword language.
Redact or Remove Personally Identifiable Information (PII)
SWIRL supports PII removal and redaction using Microsoft Presidio.
RemovePIIQueryProcessor (Redacts Queries)
Removes PII before querying.
Enable for a Specific SearchProvider:
"query_processors": [
"AdaptiveQueryProcessor",
"RemovePIIQueryProcessor"
]
Enable for ALL SearchProviders:
Add RemovePIIQueryProcessor as a stage of the System Default Pre-Query Pipeline in the Django Admin.
More details: ResultProcessors
RedactPIIResultProcessor (Redacts Results)
Redacts PII in results (e.g., "James T. Kirk" → "<PERSON>").
Enable for a Specific SearchProvider:
"result_processors": [
"MappingResultProcessor",
"DateFinderResultProcessor",
"CosineRelevancyResultProcessor",
"RedactPIIResultProcessor"
]
More details: ResultProcessors
RedactPIIPostResultProcessor
This processor applies PII redaction after all results are processed.
Understand the Explain Structure
The CosineRelevancyPostResultProcessor outputs a JSON structure explaining swirl_score calculations.
Viewing the Explain Data:
- Enabled by default.
- To disable, add
&explain=Falseto the mixer URL.
Example:
{
"swirl_rank": 1,
"swirl_score": 24911.43237469431,
"searchprovider": "News - Google News",
"title": "Maryland unveils statewide zero-trust <em>cybersecurity</em> <em>policy</em> - S",
"url": "https://news.google.com/rss/articles/CBMijgFBVV95cUxOR2VDaEJaU1ZVNzg4X...",
"date_published": "2026-02-24 08:00:00+00:00",
"author": "StateScoop",
"swirl_id": 5,
"explain": {
"stems": "cybersecur polici",
"title": {
"cybersecurity_policy_*": 0.7592695951461792,
"cybersecurity_policy_4": 0.9999997019767761,
"cybersecurity_4": 0.5741930603981018,
"policy_5": 0.7509340047836304,
"result_length_adjust": 1.5714285714285714,
"query_length_adjust": 1.0
},
"body": {
"cybersecurity_policy_*": 0.7592695951461792,
"cybersecurity_policy_4": 0.9999997019767761,
"cybersecurity_4": 0.5741930603981018,
"policy_5": 0.7509340047836304,
"result_length_adjust": 22.714285714285715,
"query_length_adjust": 1.0
},
"hits": {
"title": {
"cybersecurity": [
4
],
"policy": [
5
]
},
"body": {
"cybersecurity": [
4
],
"policy": [
5
]
},
"author": []
}
}
}
Explain Match Types:
| Postfix | Meaning | Example |
|---|---|---|
_* |
Query partially matched against the entire result field. | "knowledge_management_*", 0.7332... |
_s* |
Query matched one or more sentences, highest similarity recorded. | "knowledge_management_s*", 0.7332... |
_n |
Query matched at word position 'n' in the field. |
"Knowledge_Management_0", 0.7332... |
Additional Data:
stems→ Shows matching stems.resultandquerylength adjustments are recorded.hits→ Displays zero-offset token positions for each match.
Develop New Connectors
To connect to a new endpoint using an existing Connector (e.g., RequestsGet), create a new SearchProvider instead.
Example: The Google PSE SearchProvider JSON demonstrates how one Connector can be used to define hundreds of SearchProviders.
When to Develop a New Connector
Create a new Connector if: - The target API requires a unique transport method not supported by existing connectors. - A high-quality Python package exists to interface with the API.
Connector Base Class
All Connectors extend the Connector base class, which defines the workflow in federate().
Source: swirl/connectors.
Connector Workflow (federate() Method)
def federate(self):
'''
Executes the workflow for a given search and provider
'''
self.start_time = time.time()
if self.status == 'READY':
self.status = 'FEDERATING'
try:
self.process_query()
self.construct_query()
if self.validate_query():
self.execute_search()
if self.status == 'FEDERATING':
self.normalize_response()
self.process_results()
if self.status == 'READY':
return self.save_results()
else:
self.error('validate_query() failed')
except Exception as err:
self.error(f'{err}')
return False
Connector Execution Stages
| Stage | Description | Notes |
|---|---|---|
| process_query | Calls the Query Processor to adapt the query for this SearchProvider. | |
| construct_query | Assembles the final query format. | |
| validate_query | Checks if the query is valid and error-free. | Returns False if invalid. |
| execute_search | Connects to the SearchProvider, executes the query, and stores the response. | |
| normalize_response | Transforms the provider’s response into JSON format for SWIRL. | |
| process_results | Runs Result Processors to map data to SWIRL’s schema. | |
| save_results | Saves results in the Django database. |
A new Connector must override:
- execute_search() → Handles the API connection & query execution.
- normalize_response() → Converts raw API responses into structured JSON.
Connector Development Guidelines
- Import new connectors in
swirl/connectors/__init__.py. - Register new processors in
CHOICESinsideswirl/models.py(requires a database migration). - Limit imports to only the required libraries (e.g.,
requests,elasticsearch,sqlite3). - To extend an existing transport, subclass it and override
normalize_response(). - Ensure
execute_search()supports: results_per_query> 10 (handle paging if needed).- Date sorting (if supported by the data source).
Using eval_credentials for Secure Authentication
To use session-based credentials dynamically in a SearchProvider:
- Store the authentication token in a session variable.
- Use
eval_credentialsto inject it into the SearchProvider.
Example:
{
"eval_credentials": "session['my-connector-token']",
"credentials": "myusername:{credentials}"
}
Required Query Mappings
When developing a new Connector, implement query_mappings:
DATE_SORT→ Enables date-based sorting.PAGE→ Enables pagination support.NOT_CHAR/NOT→ Defines negation behavior.
Required Result Processing
Each Connector should process results using a Result Processor, ideally:
"result_processors": [
"MappingResultProcessor"
]
More details: MappingResultProcessor.
Develop New Processors
Processor classes are located in: swirl/processors.
Key Guidelines:
- Processors execute in sequence and should perform one transformation only.
- Inherit from QueryProcessor, ResultProcessor, or PostResultProcessor.
- Override process() for simple changes or define new variables in __init__.
- Use validate() to check input values.
- Return: Processed data (for Query/Result processors) or an integer count of results updated (for PostResultProcessors).
Development Notes:
- Import new processors in:
swirl/processors/__init__.py. - Register processors in
CHOICESinside:swirl/models.py(requires a database migration). - PostResultProcessors should be the only processors accessing model data.
- Ensure
process()returns either: - Processed data (Query/Result processors).
- Number of updated results (PostResultProcessors).
- Use helper functions in:
swirl/processors/utils.py.
Develop New Mixers
Mixer classes are located in: swirl/mixers.
Mixer Workflow
def mix(self):
'''
Executes the workflow for a given mixer
'''
self.order()
self.finalize()
return self.mix_wrapper
- Most Mixers override
order(). order()should sort and saveself.all_resultsintoself.mixed_results.
Example: Basic Paging Mixer
def order(self):
'''
Orders all_results into mixed_results
Base class, intended to be overridden!
'''
self.mixed_results = self.all_results[(self.page-1)*self.results_requested:(self.page)*self.results_requested]
Example: RelevancyMixer
class RelevancyMixer(Mixer):
type = 'RelevancyMixer'
def order(self):
# Sort results by SWIRL score, then by SearchProvider rank
self.mixed_results = sorted(
sorted(self.all_results, key=itemgetter('searchprovider_rank')),
key=itemgetter('swirl_score'),
reverse=True
)
Finalizing Results
finalize()trimsself.mixed_results, adds metadata, and returnsmix_wrapper.- Mixers automatically page results if enough are available.
Development Notes:
- Import new mixers in:
swirl/mixers/__init__.py. - Register mixers in
CHOICESinside:swirl/models.py(requires a database migration).
Using Query Transformations
Query Transformation Rules
Developers can apply query transformation rules using the Query Transformation feature.
- Pre-query rules → Apply before queries are sent to all sources.
- Per-source rules → Apply to individual SearchProviders.
Supported Transformation Types:
| Type | Description |
|---|---|
Rewrite (rewrite) |
Replaces a string in the query (or removes it entirely). |
| Synonym | Replaces a term with an OR expression containing synonyms. |
| Synonym Bag | Expands a term into an OR expression containing multiple synonyms. |
Rules are provided as CSV files uploaded to SWIRL.
Replace/Rewrite Rules
CSV Format:
| Column 1 | Column 2 |
|---|---|
List of patterns to replace (separated by ;). Supports * wildcards (non-leading). |
Replacement string (leave blank to remove the term). |
Example Configuration:
## column1, column2
mobiles; ombile; mo bile, mobile
computers, computer
cheap* smartphones, cheap smartphone
on
Example Transformations:
| Query | Transformed Query |
|---|---|
mobiles |
mobile |
ombile |
mobile |
mo bile |
mobile |
on computing |
computing |
cheaper smartphones |
cheap smartphone |
computers go figure |
computer go figure |
Synonym Rules
CSV Format:
| Column 1 | Column 2 |
|---|---|
| Term | Synonym |
Example Configuration:
## column1, column2
notebook, laptop
laptop, personal computer
pc, personal computer
personal computer, pc
car, ride
Example Transformations:
| Query | Transformed Query |
|---|---|
notebook |
(notebook OR laptop) |
pc |
(pc OR personal computer) |
personal computer |
(personal computer OR pc) |
I love my notebook |
I love my (notebook OR laptop) |
This pc, it is better than a notebook |
This (pc OR personal computer), it is better than a (notebook OR laptop) |
My favorite song is "You got a fast car" |
My favorite song is "You got a fast (car OR ride)" |
Synonym Bag Rules
CSV Format:
| Column 1 | Column 2...N |
|---|---|
| Term | List of synonyms |
Example Configuration:
## column1, column2, column3, column4
notebook, personal computer, laptop, pc
car, automobile, ride
Example Transformations:
| Query | Transformed Query |
|---|---|
car |
(car OR automobile OR ride) |
automobile |
(automobile OR car OR ride) |
ride |
(ride OR car OR automobile) |
pimp my ride |
pimp my (ride OR car OR automobile) |
automobile, yours is fast |
(automobile OR car OR ride), yours is fast |
I love the movie The Notebook |
I love the movie The Notebook |
My new notebook is slow |
My new (notebook OR personal computer OR laptop OR pc) is slow |
Uploading a Query Transformation CSV
- Log in as an
adminuser on the SWIRL homepage. - Select Upload Query Transform CSV:

- Enter a Name and select a Type:

- Choose the CSV file to upload:

- Click Upload:

Using the Uploaded CSV
Once uploaded, reference the file as <name>.<type>.
Example: If the file was named TestQueryTransform with type synonym, the reference is:
TestQueryTransform.synonym
Pre-Query Processing
Apply query transformations before execution:
Option 1: Use pre_query_processor in the API
/api/swirl/search/?q=notebook&pre_query_processor=TestQueryTransform.synonym
Option 2: Update the SWIRL Search Object
Modify pre_query_processors in the Search object to include the transformation.
More details: Creating a Search Object with the API.
Query Processing
Update the SearchProvider’s query_processors field:
{
"name": "TEST Web (Google PSE) with synonym processor",
"active": "true",
"default": "true",
"connector": "RequestsGet",
"query_processors": [
"AdaptiveQueryProcessor",
"TestQueryTransform.synonym"
],
"query_mappings": "cx=0c38029ddd002c006,DATE_SORT=sort=date,PAGE=start=RESULT_INDEX,NOT_CHAR=-",
"result_processors": [
"MappingResultProcessor",
"CosineRelevancyResultProcessor"
]
}
Integrate Source Synonyms into SWIRL Relevancy
SWIRL can extract source-specific synonym feedback and integrate it into relevancy scoring.
Why?
Some search engines apply synonyms internally (e.g., notebook → laptop), but SWIRL’s relevancy scoring is not aware of these extra terms. Hit highlighting extraction enables SWIRL to detect them.
Supported SearchProviders
- OpenSearch
- Elasticsearch
- Solr
Configuration
1. Enable Hit Highlighting in the SearchProvider
Modify the query_template to enable hit highlighting on all fields:
"query_template": {
"highlight": { "fields": { "*": {} } }
}
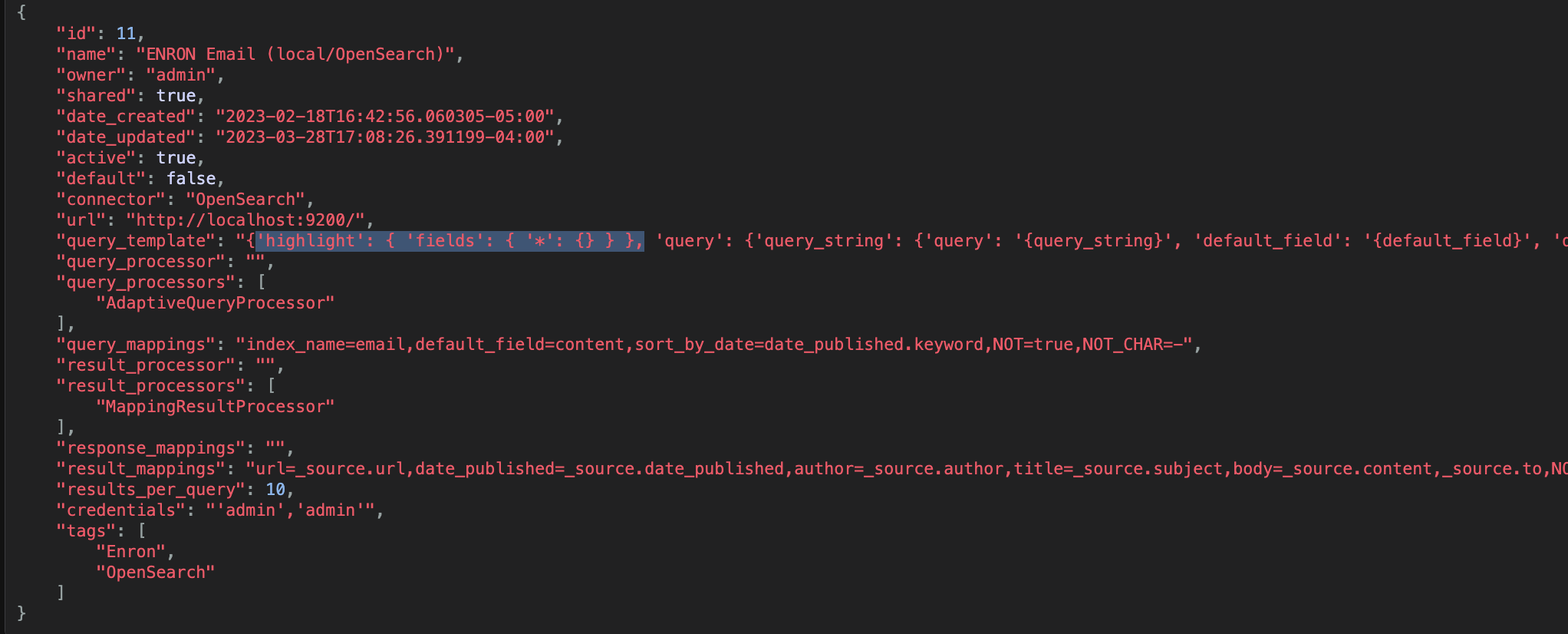
Consult the search engine’s documentation for additional highlighting options.
2. Map Highlighted Fields in results_mapping
Assign highlighted synonyms to the following SWIRL result fields:
title_hit_highlightsbody_hit_highlights
Example: Elasticsearch Response
{
"_source": {
"title": "Laptop computer",
"content": "I need a new laptop computer for work."
},
"highlight": {
"title": ["<em>Notebook</em> computer"],
"content": ["I need a new <em>notebook</em> computer for work."]
}
}
Mapping Configuration in results_mapping
title_hit_highlights=highlight.title, body_hit_highlights=highlight.content

Results
The configuration appears in the info section of the results:
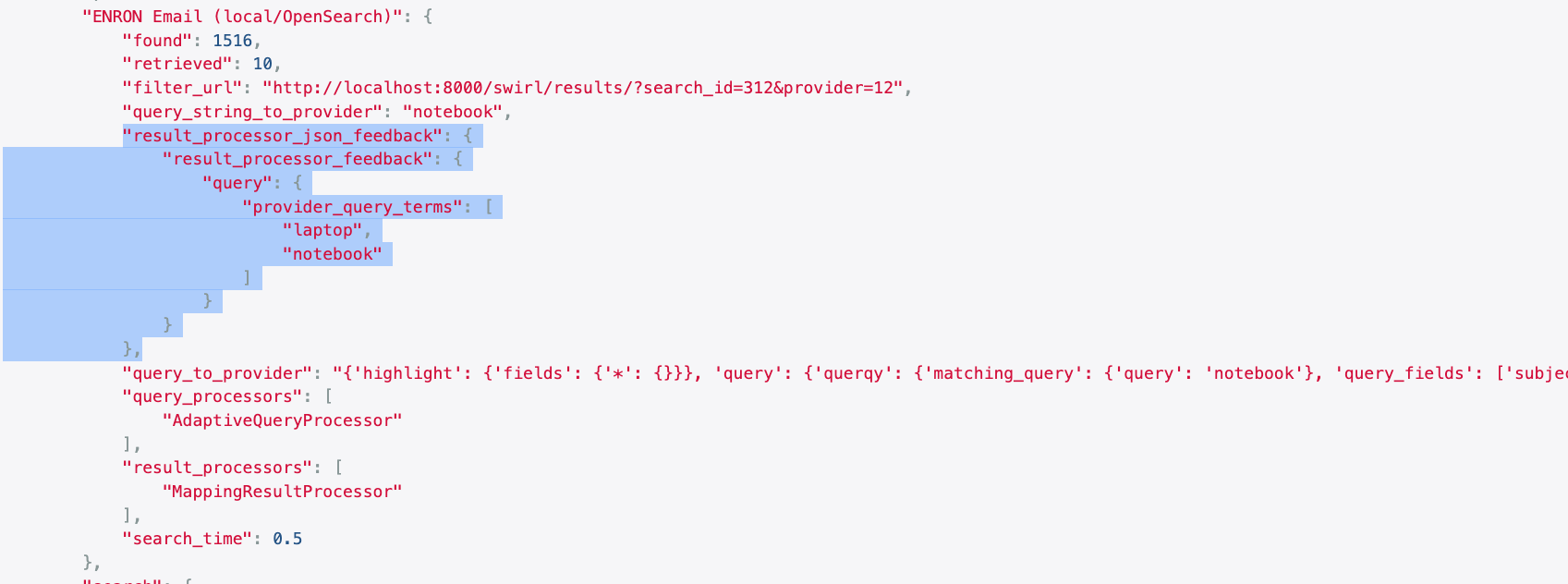
- The original query term was
"notebook". - The search engine used
"laptop"as a synonym. - Both terms were extracted and used in SWIRL's relevancy ranking.
Complete Highlighted Synonyms
The full hit highlighting content is available in:
body_hit_highlights→ Synonym highlights in content.title_hit_highlights→ Synonym highlights in titles.

Example Search Objects
Basic Search
Runs a default configuration:
- Retrieves 10 results.
- Uses the RelevancyConfidenceMixer.
{
"query_string": "search engine"
}
Run as a GET request
Using the q= URL parameter:
http://localhost:8000/swirl/search?q=search+engine
Using NOT Queries
{
"query_string": "search engine -SEO"
}
{
"query_string": "generative ai NOT chatgpt"
}
Note:
- SWIRL may rewrite these queries based on query_mappings in the SearchProvider.
- See: Search Syntax.
Sorting by Date
{
"query_string": "search engine",
"sort": "date"
}
Using the DateMixer (instead of RelevancyMixer)
{
"query_string": "search engine",
"sort": "date",
"result_mixer": "DateMixer"
}
Spellcheck Example
{
"query_string": "search engine",
"pre_query_processors": ["SpellcheckQueryProcessor"]
}
- Spellcheck runs before federated search.
- The corrected query is sent to each SearchProvider.
- Not recommended for Google PSE, as it handles spellchecking natively.
Searches specifying "sort", "result_mixer", or "pre_query_processors" must be POSTed to the Search API.
Advanced Search Example
This request:
- Retrieves 20 results.
- Queries SearchProviders 1 & 3 only.
- Uses the RoundRobinMixer instead of relevancy ranking.
- Sets a retention time of 1 hour.
{
"query_string": "search engine",
"results_requested": 20,
"searchprovider_list": [1, 3],
"result_mixer": "RoundRobinMixer",
"retention": 1
}
Retention setting (retention: 1) ensures the search is deleted after 1 hour, assuming the Search Expiration Service is running.
Funding Dataset Examples
If the Funding Dataset is installed, the following queries work:
electric vehicle company:tesla
social media company:facebook
company:slack