AI Search Guide
Please contact SWIRL for access to SWIRL Enterprise.
Configuring SWIRL AI Search, Enterprise Edition
Licensing
Add the license provided by SWIRL to the installation's .env file in the following format:
SWIRL_LICENSE={"owner": "<owner-name>", "expiration": "<expiration-date>", "key": "<public-key>"}
If the license is invalid, a message appears in logs/django.log. Contact support for assistance.
Database
For Proof of Value (POV) testing, SWIRL Enterprise can use SQLite3. Contact support for help configuring it.
For production, SWIRL recommends PostgreSQL.
PostgreSQL Configuration
Modify the database settings in swirl_server/settings.py:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': '<database-name>',
'USER': '<database-username>',
'PASSWORD': '<database-password>',
'HOST': '<database-hostname>',
'PORT': '<database-port>',
}
}
Connecting to M365
To connect SWIRL to your Microsoft 365 (M365) tenant, see the Microsoft 365 Guide.
Connecting to Other Authentication Systems
To integrate SWIRL with an Identity Provider (IDP) or Single Sign-On (SSO) system, configure an Authenticator object.
Managing Authenticators
Use the Admin Console at http://localhost:8000/admin/swirl to view, edit, add, or delete authenticators.
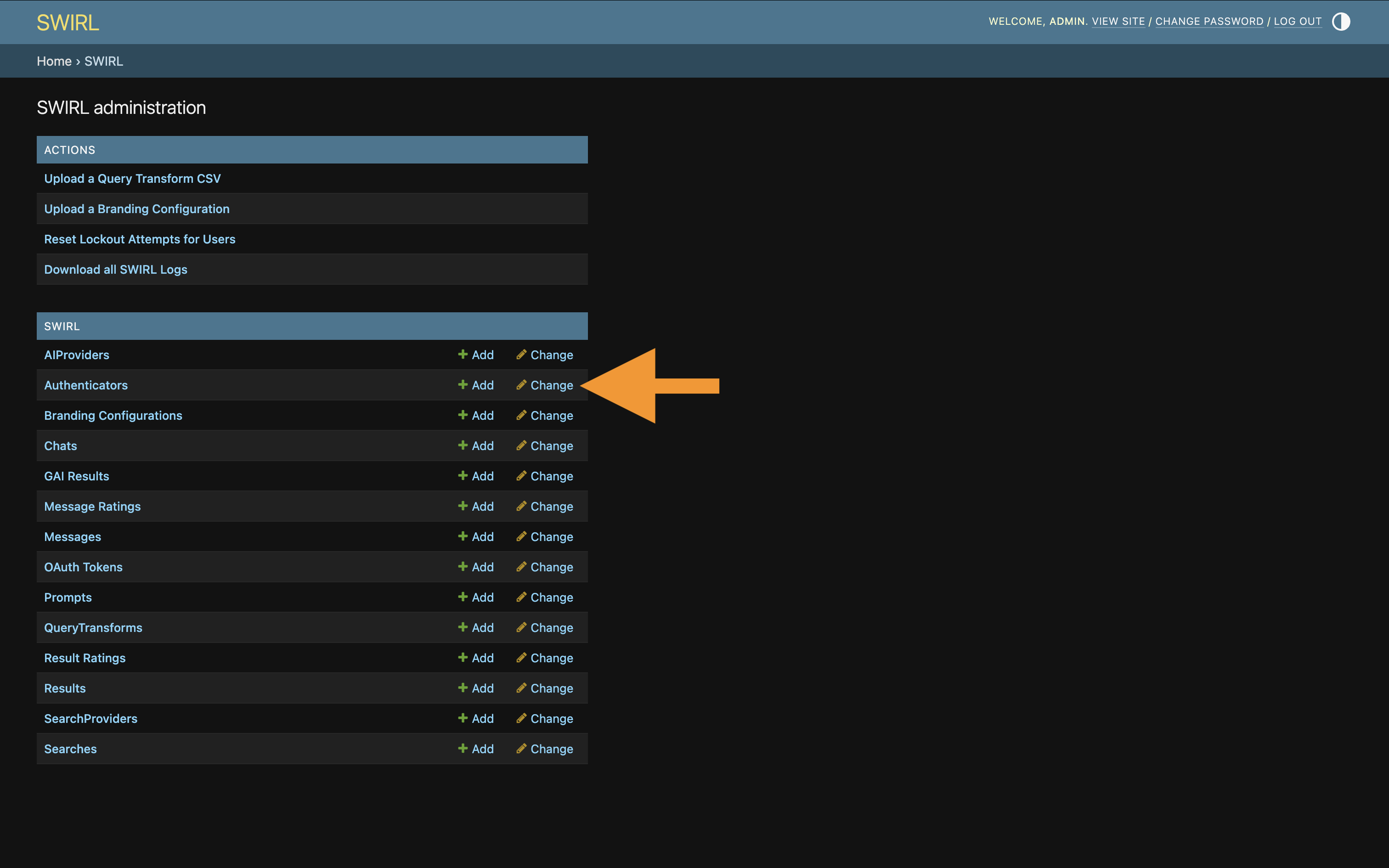
Click Authenticators to view the list, or add a new one:

Click any authenticator in the list to view or edit it. For example, here's the default Microsoft authenticator:
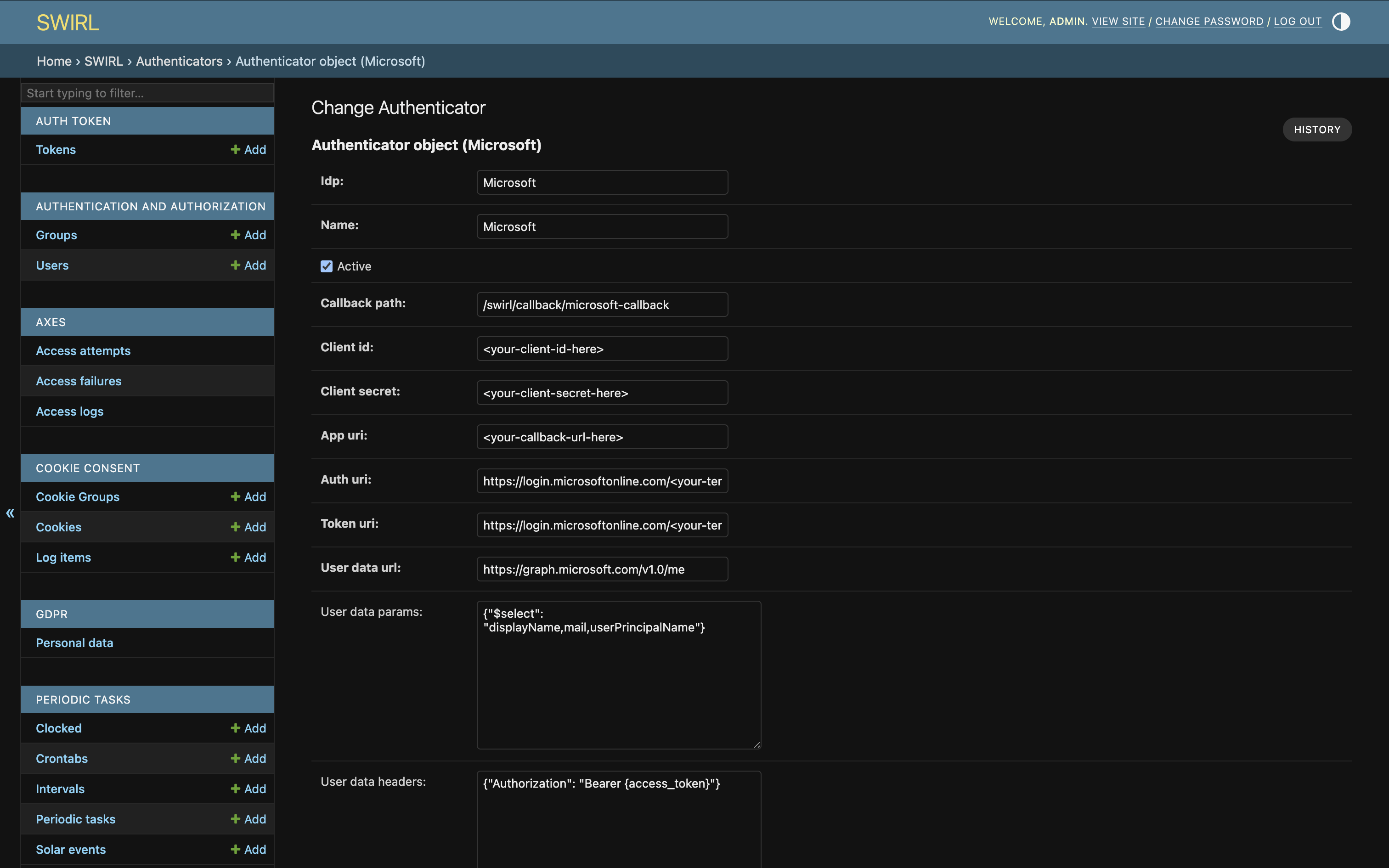
Click SAVE at the bottom of the page to commit changes.
Authenticator Fields
| Field | Description |
|---|---|
idp |
Name of the authenticator object (used as the URL) |
name |
Display name of the authenticator |
active |
Boolean; if false, the authenticator is disabled, and no authentication switch appears in the UI |
callback_path |
URL path where the IDP should redirect with user tokens |
client_id |
Client ID for authentication |
client_secret |
Shared secret for authentication |
app_uri |
Location of the SWIRL application |
auth_uri |
URL of the authentication system |
token_uri |
URL for retrieving authentication tokens |
user_data_url |
URL for retrieving user profile data |
user_data_params |
Parameters needed from the user profile |
user_data_headers |
Headers required for requesting tokens (e.g., "Authorization") |
user_data_method |
HTTP method used to request user profile data |
initiate_auth_close_flow_params |
Parameters for CAS2 and other custom authentication flows |
exchange_code_params |
Parameters for exchanging authorization codes in custom flows |
is_code_challenge |
Boolean; determines if exchange code parameters are required (default: True) |
scopes |
List of authorization scopes |
should_expire |
Boolean; determines if tokens need refreshing (default: True) |
use_basic_auth |
Boolean; enables basic authentication instead of SSO |
For authentication with Elastic, OpenSearch, CAS2, Salesforce, ServiceNow, Okta, Auth0, Ping Federate, and other systems, contact support.
OpenID Connect
OpenID Connect (OIDC) is a standard authentication protocol for secure SSO with identity providers. When you configure an OIDC-compatible authenticator in SWIRL, users can authenticate through their organization's identity provider without requiring manual account creation in SWIRL.
To configure an OpenID Connect authenticator:
- Navigate to the Admin Console at http://localhost:8000/admin/swirl.
- Click
Authenticatorsto view the available authenticators. - Either select an existing OpenID Connect authenticator to edit it, or click
Add Authenticatorto create a new one. - Configure the following fields with your provider's information:
-
auth_uri— your identity provider's authorization endpoint. -token_uri— your identity provider's token endpoint. -user_data_url— your identity provider's user info endpoint. -client_idandclient_secret— credentials provided by your identity provider. - Click
SAVEto apply changes.
When OpenID Connect is enabled and configured, users see an authentication option in the SWIRL interface that lets them log in through their organization's identity provider. Authenticated users are automatically created in SWIRL with their identity provider information.
Connecting to Generative AI (GAI) and Large Language Models (LLMs)
Roles for LLMs
LLMs in SWIRL serve four distinct roles:
| Role | Description |
|---|---|
reader |
Generates embeddings for SWIRL's Reader LLM to enhance search-result re-ranking. |
query |
Provides query completions for transformations. |
connector |
Answers direct questions without RAG. |
rag |
Generates RAG responses using retrieved data. |
Managing AI Providers
Use the Admin Console at http://localhost:8000/admin/swirl to view, add, edit, or delete AI Providers.
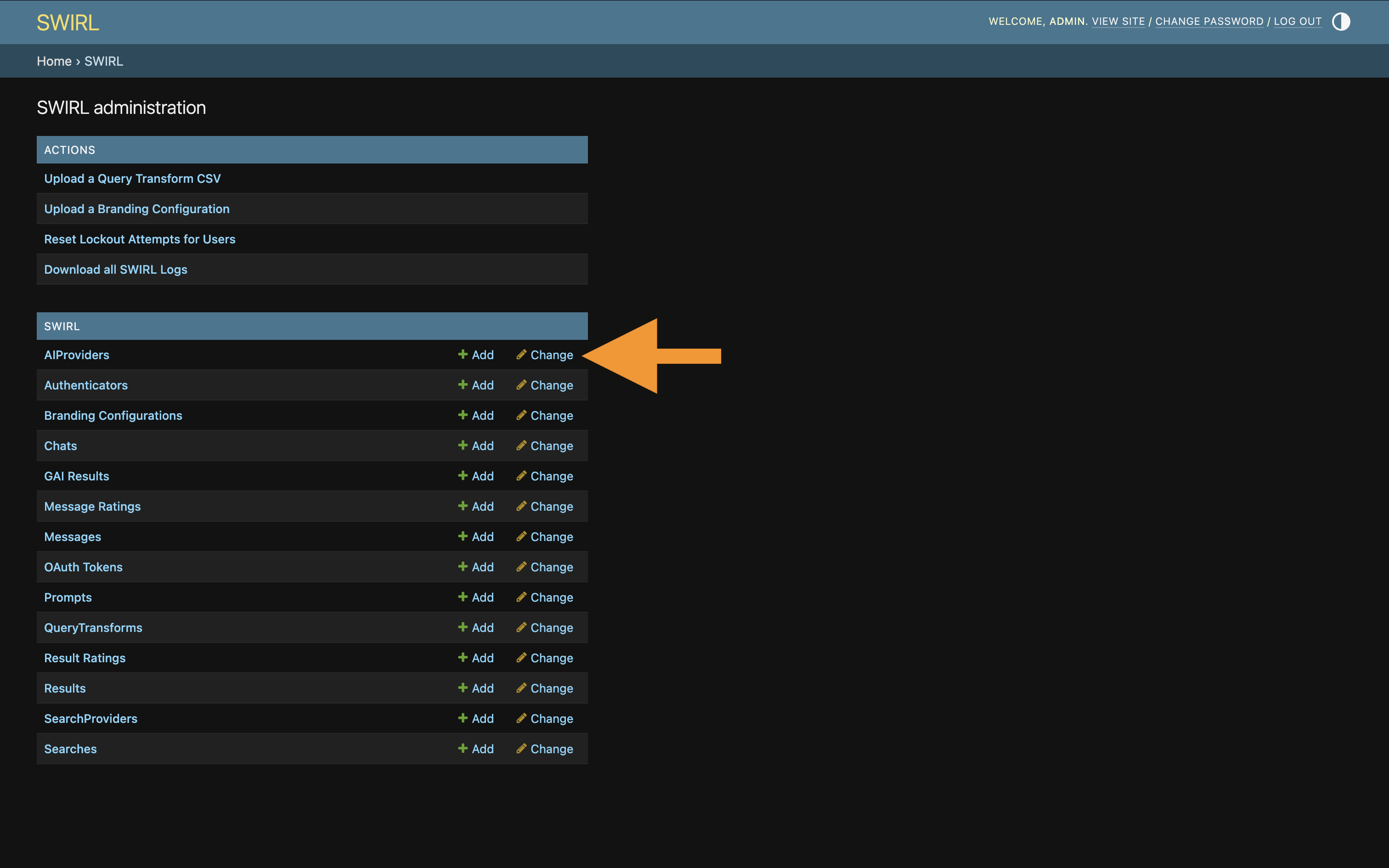
Click AIProviders to access the full list:
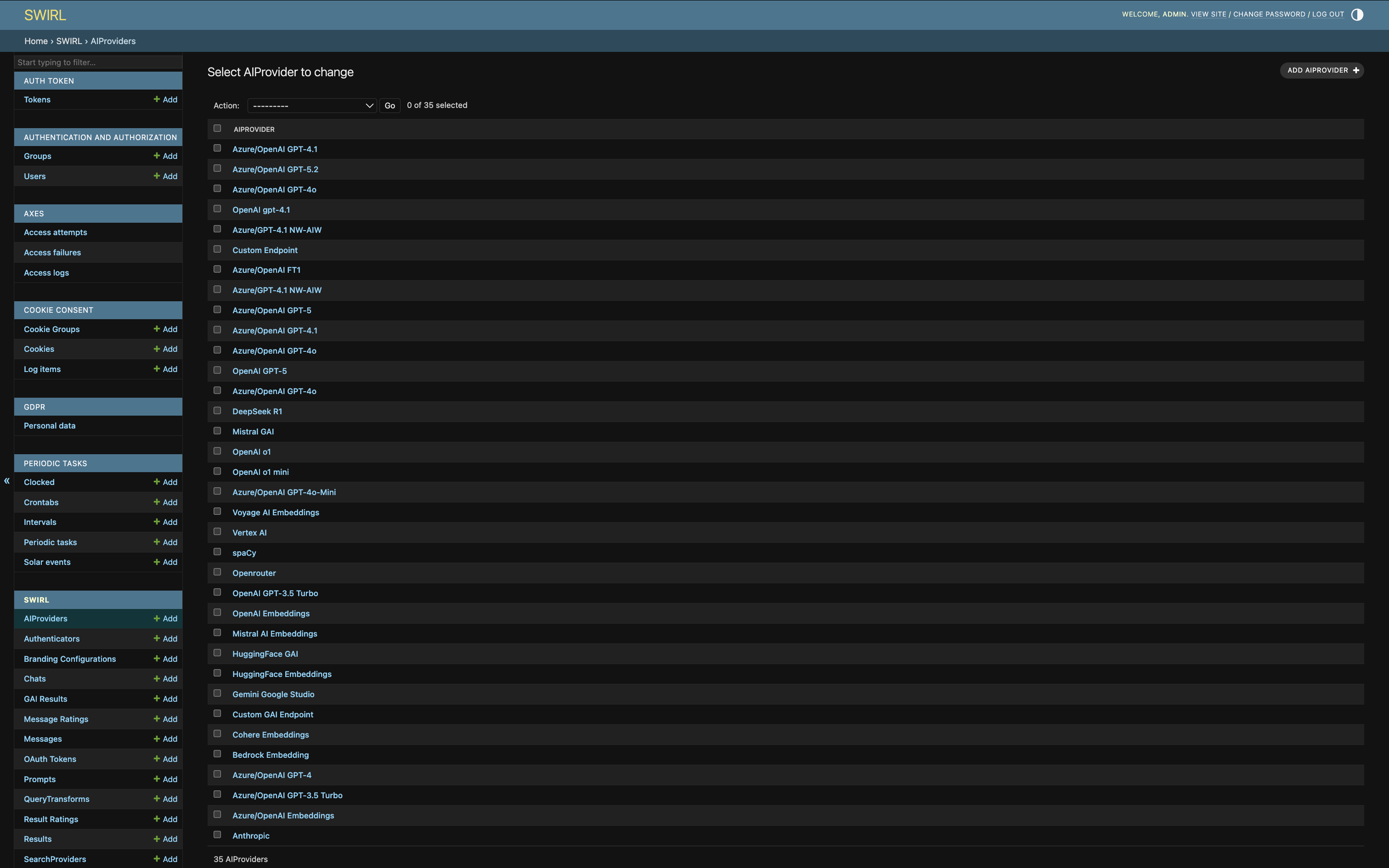
Supported LLMs
SWIRL supports major LLMs via LiteLLM and direct connections, including:
- OpenAI (ChatGPT API)
- OpenAI deployed in Azure
- AWS Bedrock
- Google Gemini
- Anthropic Claude
- Cohere
- Meta Llama
- Hugging Face
- Locally fine-tuned models
Full lists are available here:
For any of these or additional models, contact support.
Editing AI Providers
From the Admin Console, click AIProviders to view the list of all available providers. Click a specific AIProvider to edit it:
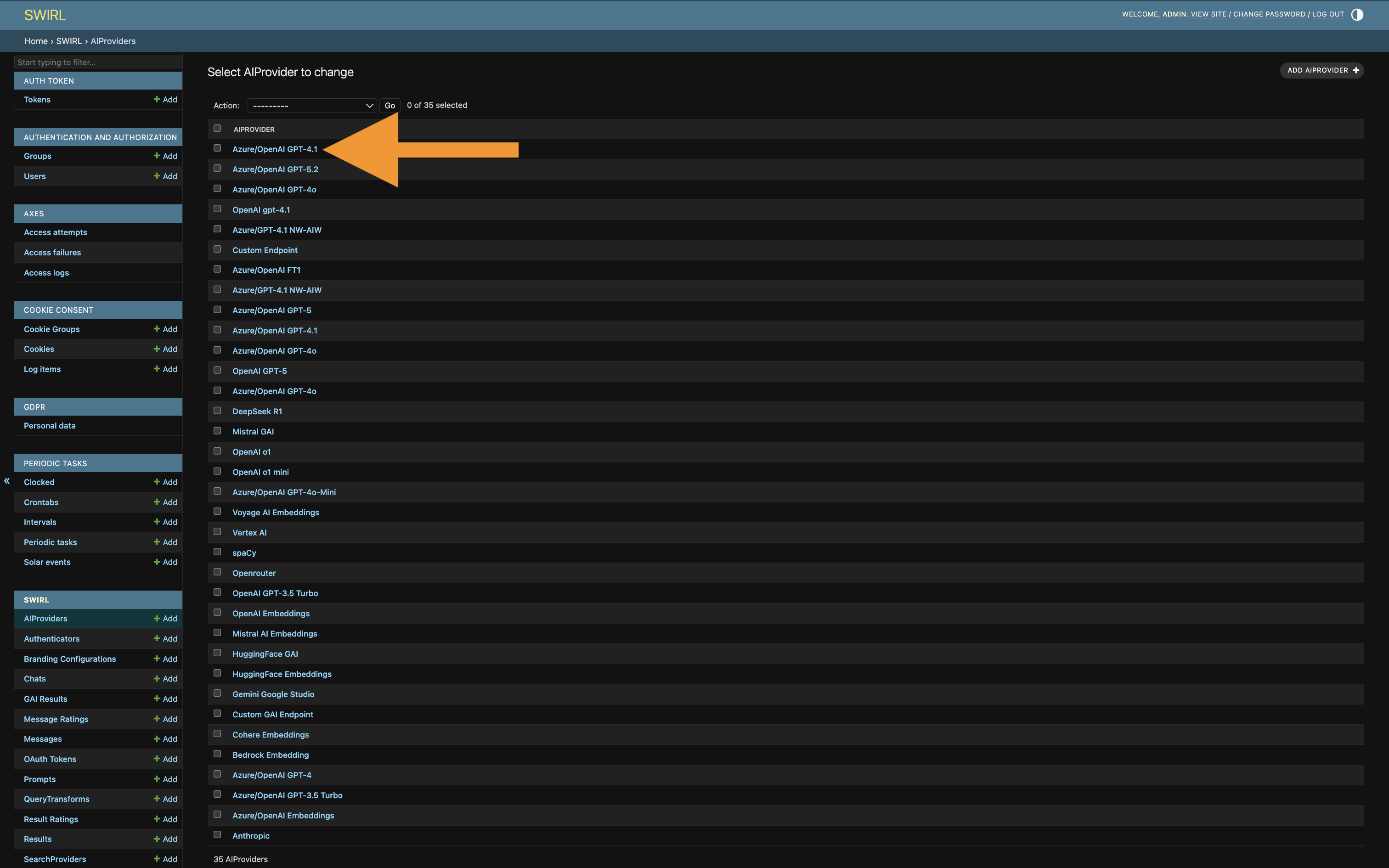
This opens an edit form:
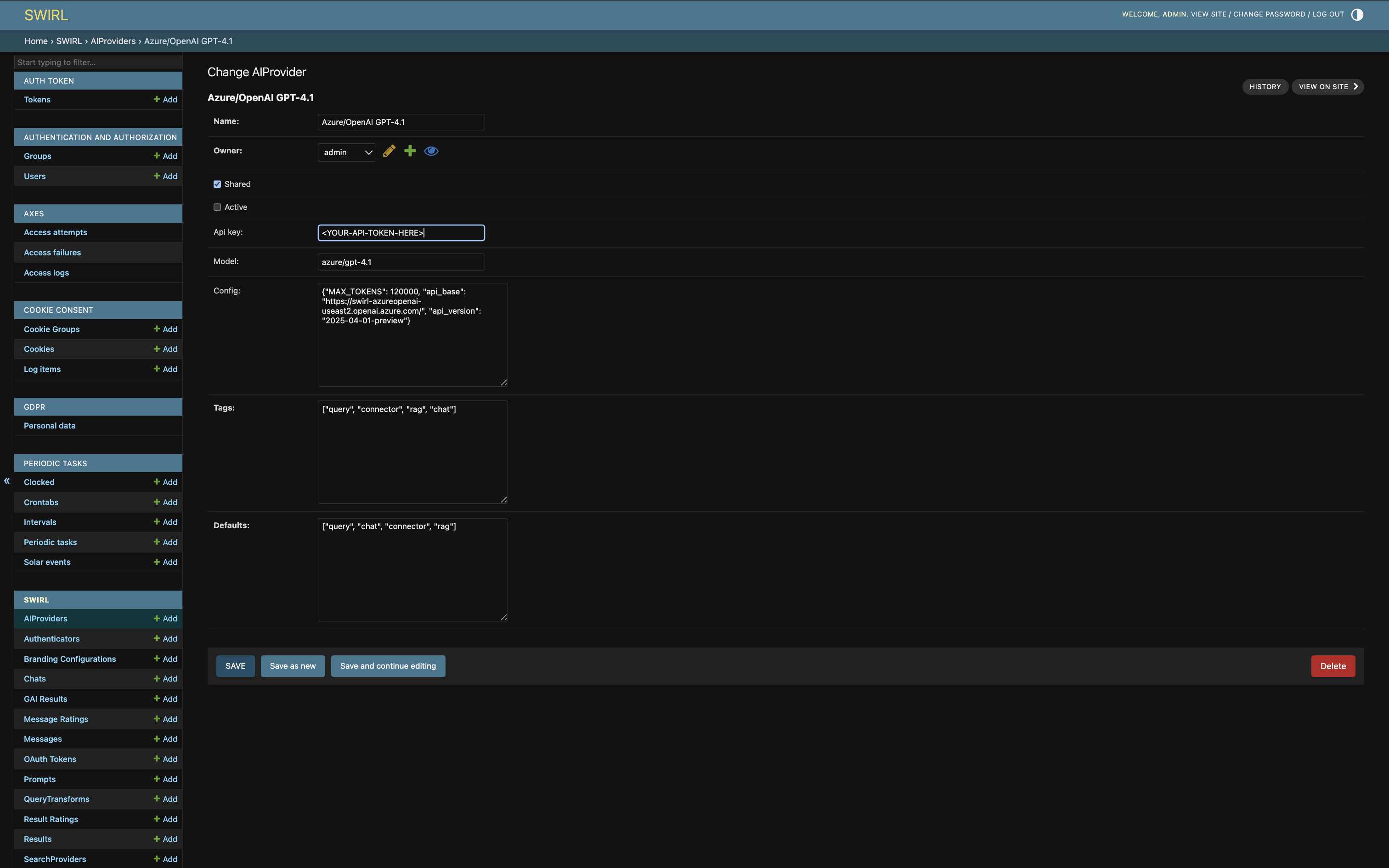
Click SAVE to commit changes.
Click Delete to remove the provider entirely. There is no undo — deleted providers are lost. To save an AIProvider without using it, set its active property to false (unchecked).
Activating AI Providers
To activate a preloaded AI provider:
- Make sure the
activeproperty is checked. - Add a valid API key to the
credentialsfield. - Set the
modeland any requiredconfigitems. - Ensure the provider has the correct
tagsanddefaultsettings.
Switching AI Provider Defaults
To switch the provider for a given role, use the active property. Only one AIProvider should be active for each system-defined role.
Adding AI Providers
Via the Admin Console
From the Admin Console, click AIProviders, then click Add AIProvider:
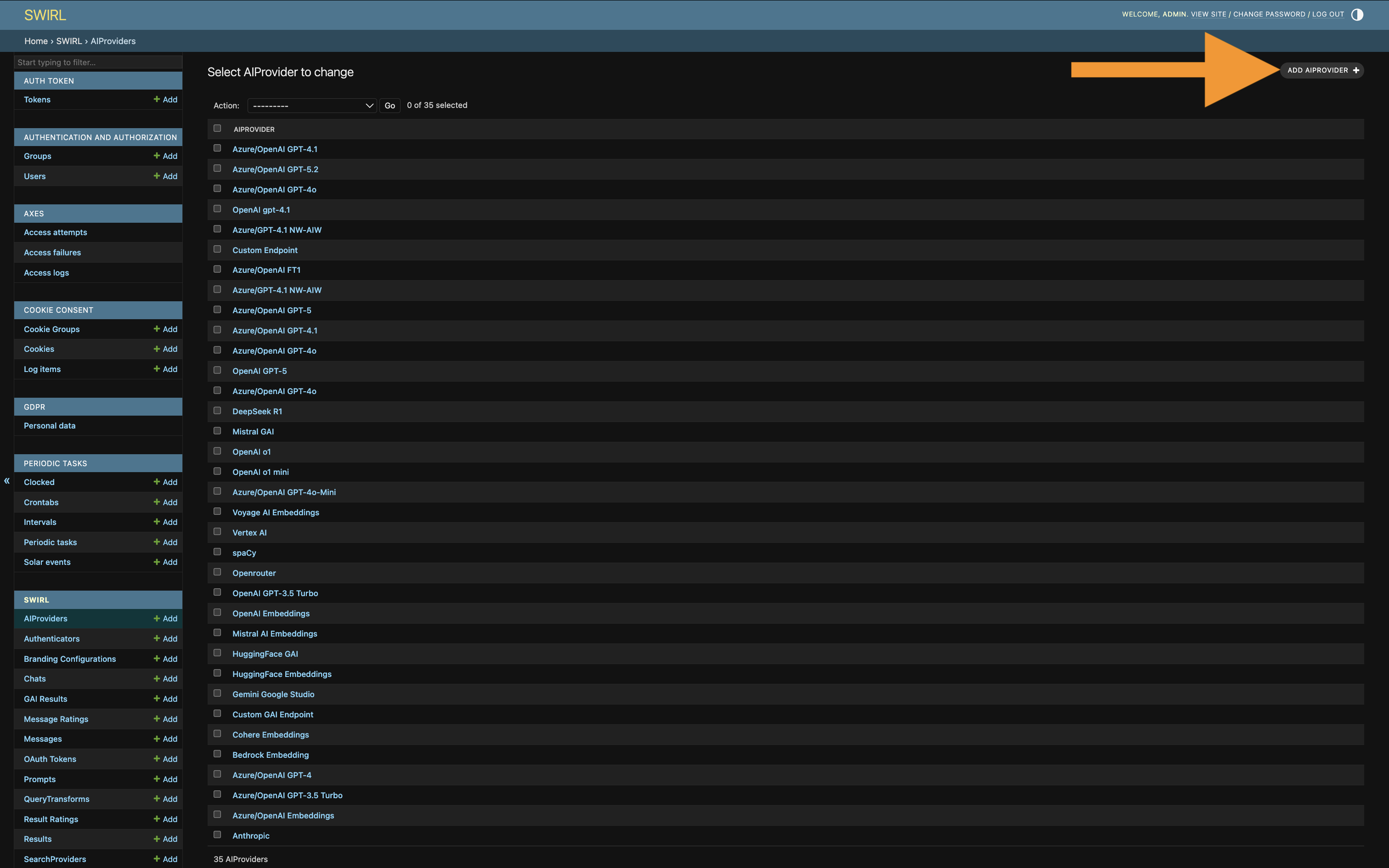
A blank form for a new AIProvider opens:
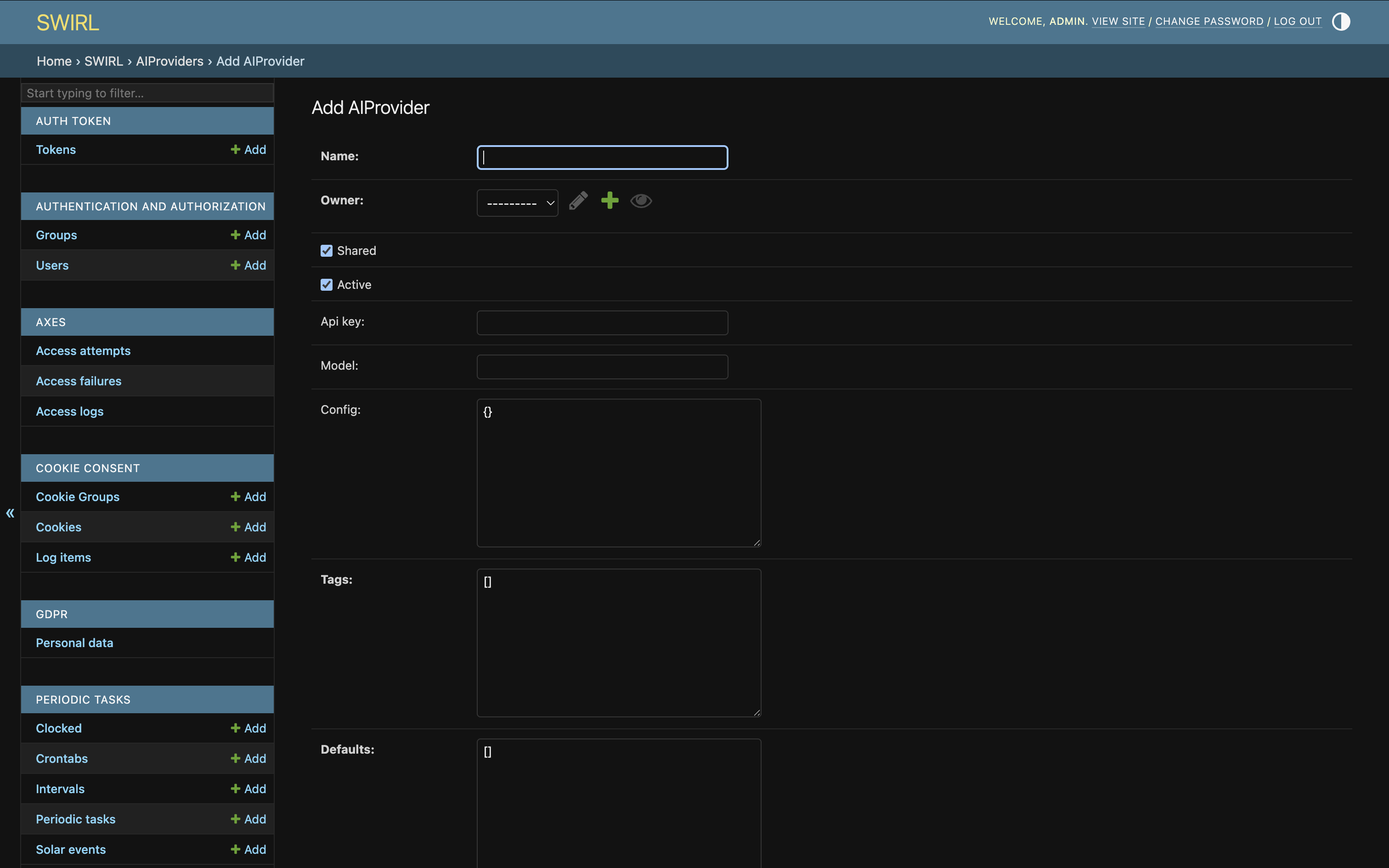
Fill out the form and click SAVE.
Via Copy/Paste
To manually install an AI provider using JSON:
- Make sure you are logged in as the
adminuser. - Open the AI Providers API endpoint: http://localhost:8000/swirl/aiproviders/.
- Click the
Raw datatab at the bottom of the page. - Paste the AI provider's JSON.
- Click
POST.
SWIRL responds with the registered AI provider.
Bulk Loading AI Providers
Use the swirl_load.py script to load multiple AI providers.
Using the Bearer Token Service to Update AI Providers
SWIRL Enterprise includes a Bearer Token Service that refreshes tokens automatically.
How It Works
- Sends a
POSTrequest to an Identity Provider (IDP) URL with user credentials. - Extracts a
bearer_tokenfrom the response. - Updates the
api_keyof the configured AI provider.
Configuration
# 1. Add the following settings to .env:
BT_IDP_URL=''
BT_IDP_CLIENT_ID=''
BT_IDP_CLIENT_SECRET=''
# 2. Specify the AI Provider IDs to update:
BT_AIP=9
For multiple providers, use a comma-separated list:
BT_AIP='9,10'
# 3. Schedule Token Refresh in swirl_server/settings.py:
By default, the service runs every 20 minutes. Adjust the schedule in CELERY_BEAT_SCHEDULE:
CELERY_BEAT_SCHEDULE = {
# Bearer Token Service (default: every 20 minutes)
'bt_service': {
'task': 'bt_service',
'schedule': crontab(minute='*/20'),
},
}
# 4. Start the celery-beats service:
python swirl.py start celery-beats
# 5. Restart the logs:
If python swirl.py logs is running, restart it to view celery-beats messages.
Most Bearer Token service logs appear in logs/celery-worker.log.
This ensures automatic updates for AI provider credentials, reducing manual intervention.
Managing Prompts
SWIRL Enterprise includes a set of pre-loaded standard prompts used when generating AI Insights via RAG.
Each consists of three key components:
| Field | Description |
|---|---|
prompt |
The main body of the prompt. Use {query} to represent the SWIRL query. |
note |
Text appended to search result data sent to the LLM for insight generation. |
footer |
Additional instructions appended after the prompt and RAG data. This is ideal for formatting guidance. |
The name of the prompt has no importance. SWIRL uses the tags field to determine which prompt is used for a given function.
The following table presents the tags options:
| Tag | LLM Role |
|---|---|
search-rag |
Used by AI Search, Generate AI Insight (RAG) switch; somewhat technical. |
chat |
Used by AI Search Assistant for chat conversations, including company background; not technical. |
chat-rag |
Used by AI Search Assistant to answer questions and summarize data via RAG; somewhat technical. |
There must be at least one active prompt for each of these tags for the relevant SWIRL features to work.
Modifying the Standard Prompts
Never modify the standard prompts. All changes are discarded when SWIRL updates. Use the Customizing Prompts procedure below instead.
Customizing the AI Search RAG Prompt
Removing important sections of a prompt — such as variables like {header} and {query} — may cause AI Insight generation to fail or to omit features like follow-up questions or citations.
The following procedure copies the standard prompts, modifies them, then activates them. New prompts are preserved across SWIRL upgrades.
-
Open the Admin Console at http://localhost:8000/admin/swirl.
-
Click
Promptsnear the bottom of the page: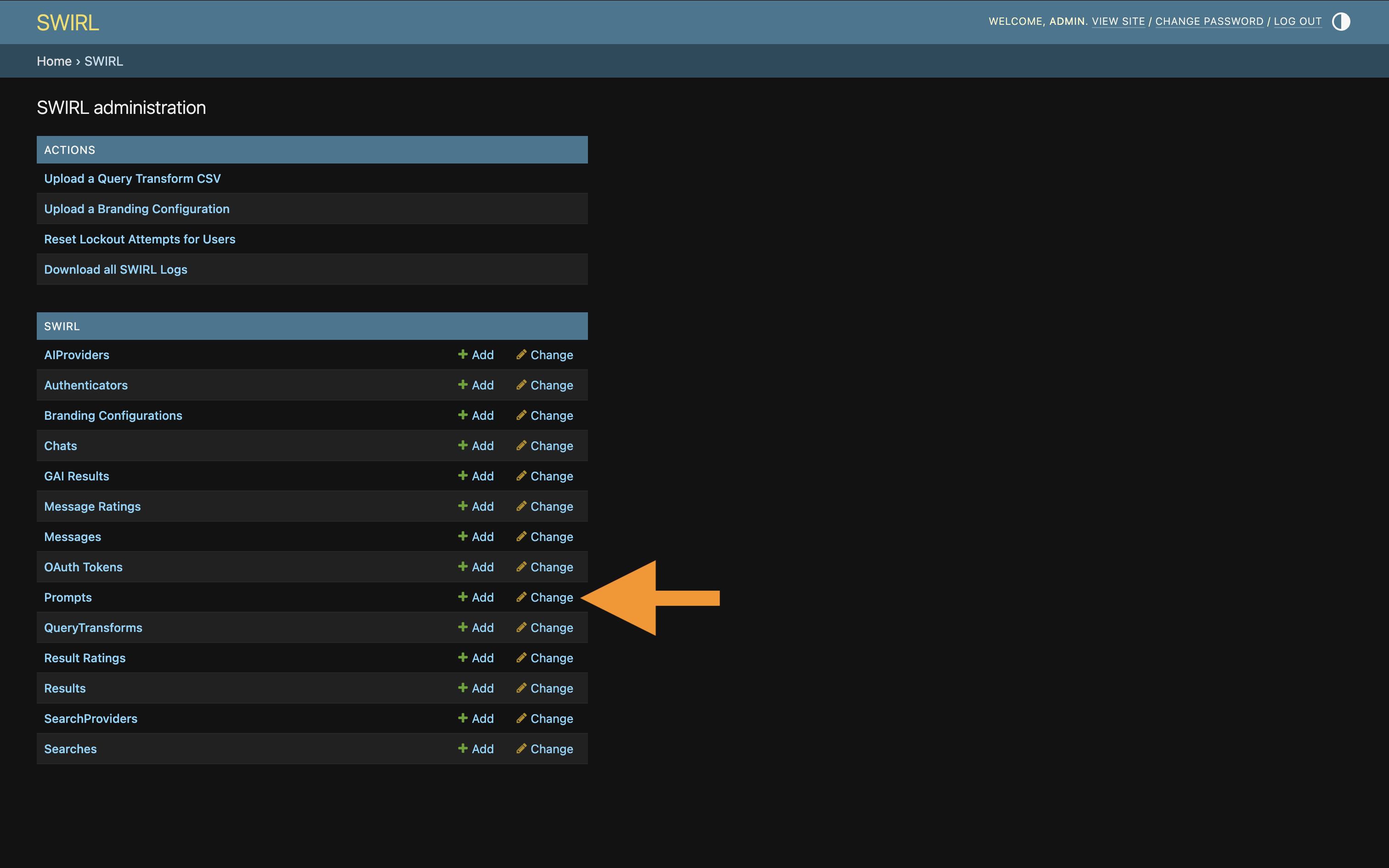
-
Click the
search_rag_standardprompt — or, if using Deep Linking, thesearch_rag_deeplinkprompt: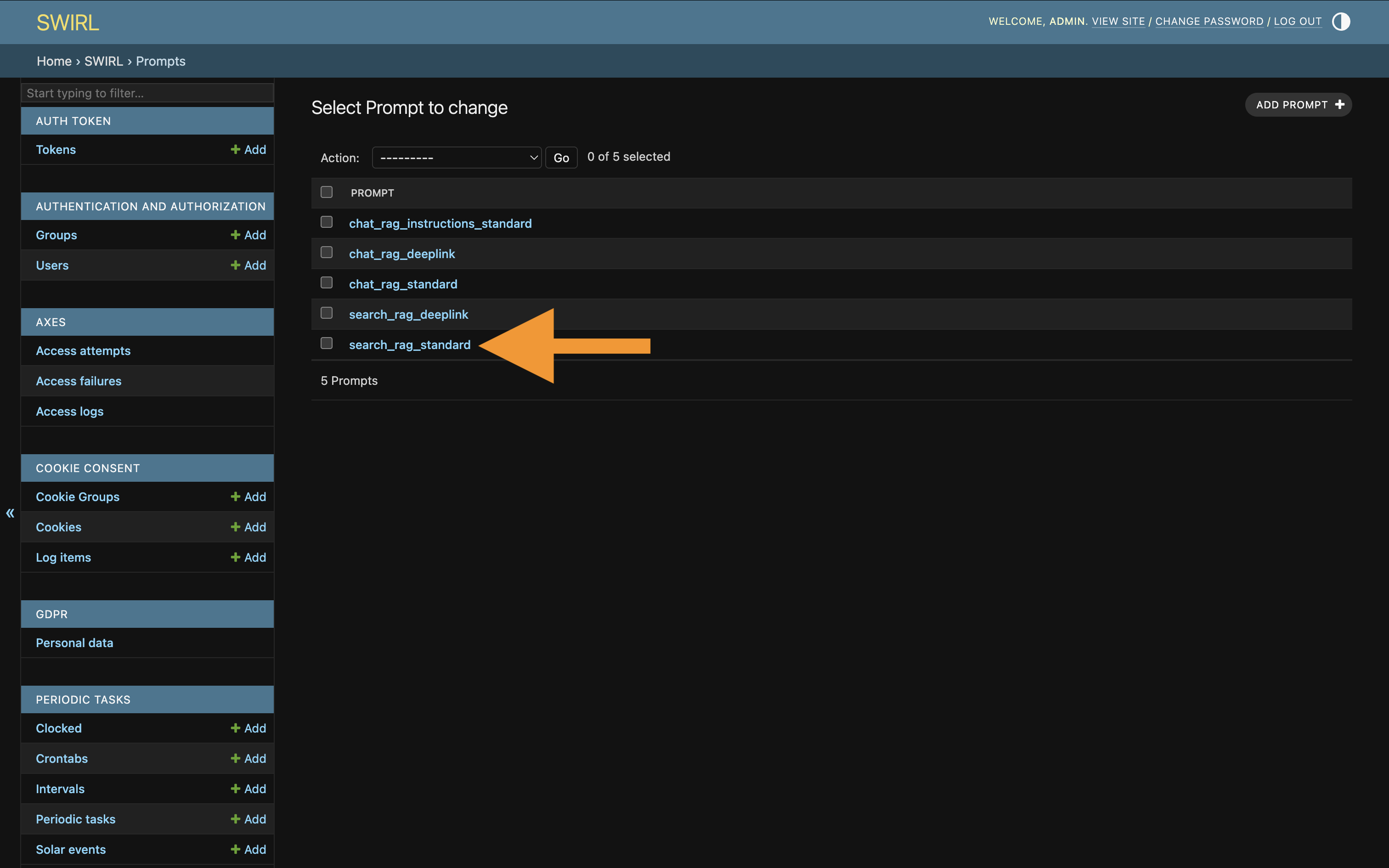
-
Using the form, uncheck
active. ClickSAVEat the bottom of the page: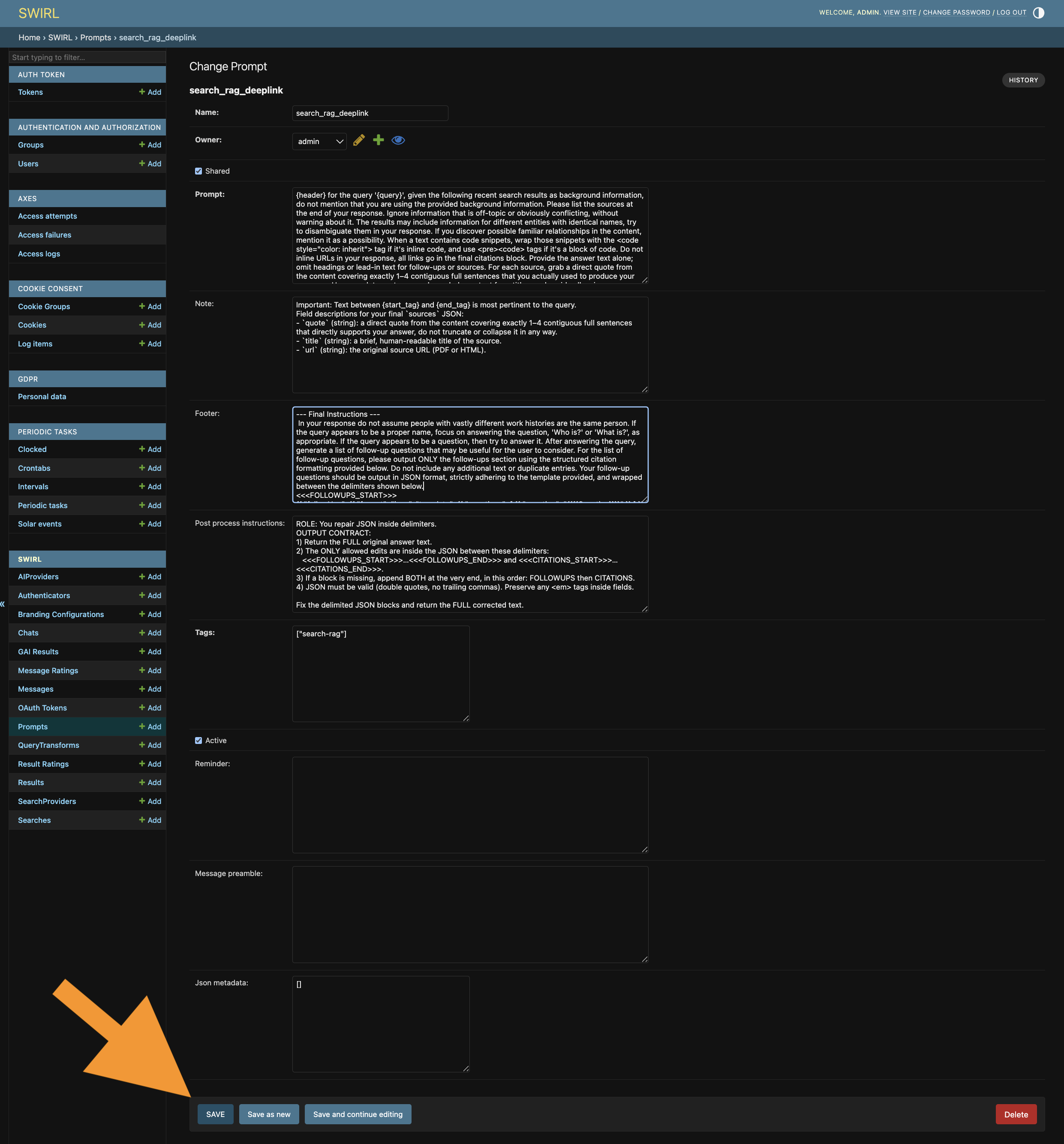
-
Change the
nameof the prompt to something appropriate likemy_custom_prompt. ClickSave as newat the bottom of the page. -
Set the prompt to
active. ClickSAVEto save the new prompt. -
If you don't wish to share this prompt with other users, set
sharedtofalse. -
Modify the
prompt,note, and/orfooteras needed, while retaining all critical instructions. For example, to instruct the LLM to use pirate-speak:
-
Click
SAVEto commit changes: -
Try the new prompt from the Galaxy Search form.
Restoring Standard Prompts
To revert to a standard prompt after creating a new one:
- Open the Admin Console and select
Prompts. - Edit the new prompt, uncheck
active, and clickSAVE. - Edit the system prompt, check
active, and clickSAVE.
Restoring All Prompts to Default
To restore all prompts to the default, see Resetting Prompts in the Admin Guide.
Specifying a Saved Prompt when Generating AI Insights
There are two ways to select a saved prompt:
- Use the prompt selector on the AI Search form:
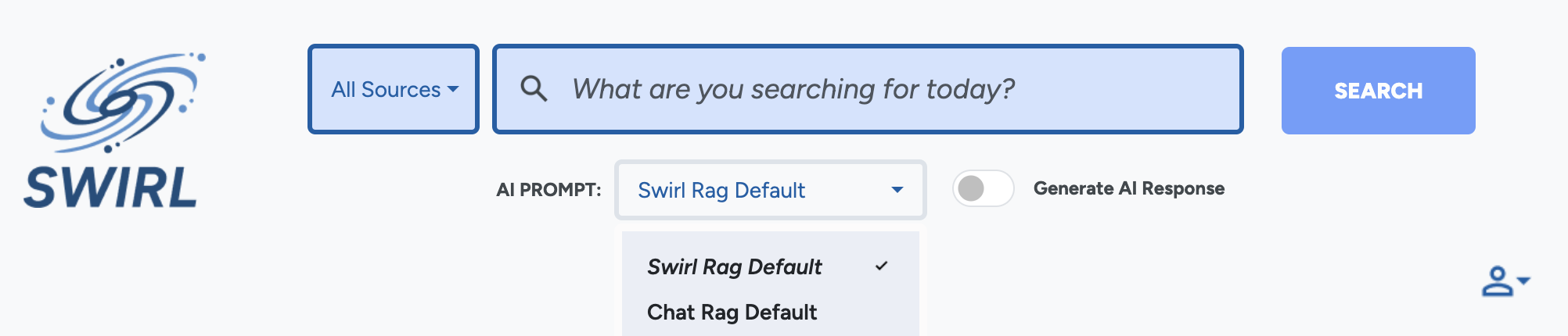
- Use the
promptoperator in your query. For example:
Swirl AI Search prompt:pirate
In either case, the response is generated in pirate-speak as the prompt instructs:
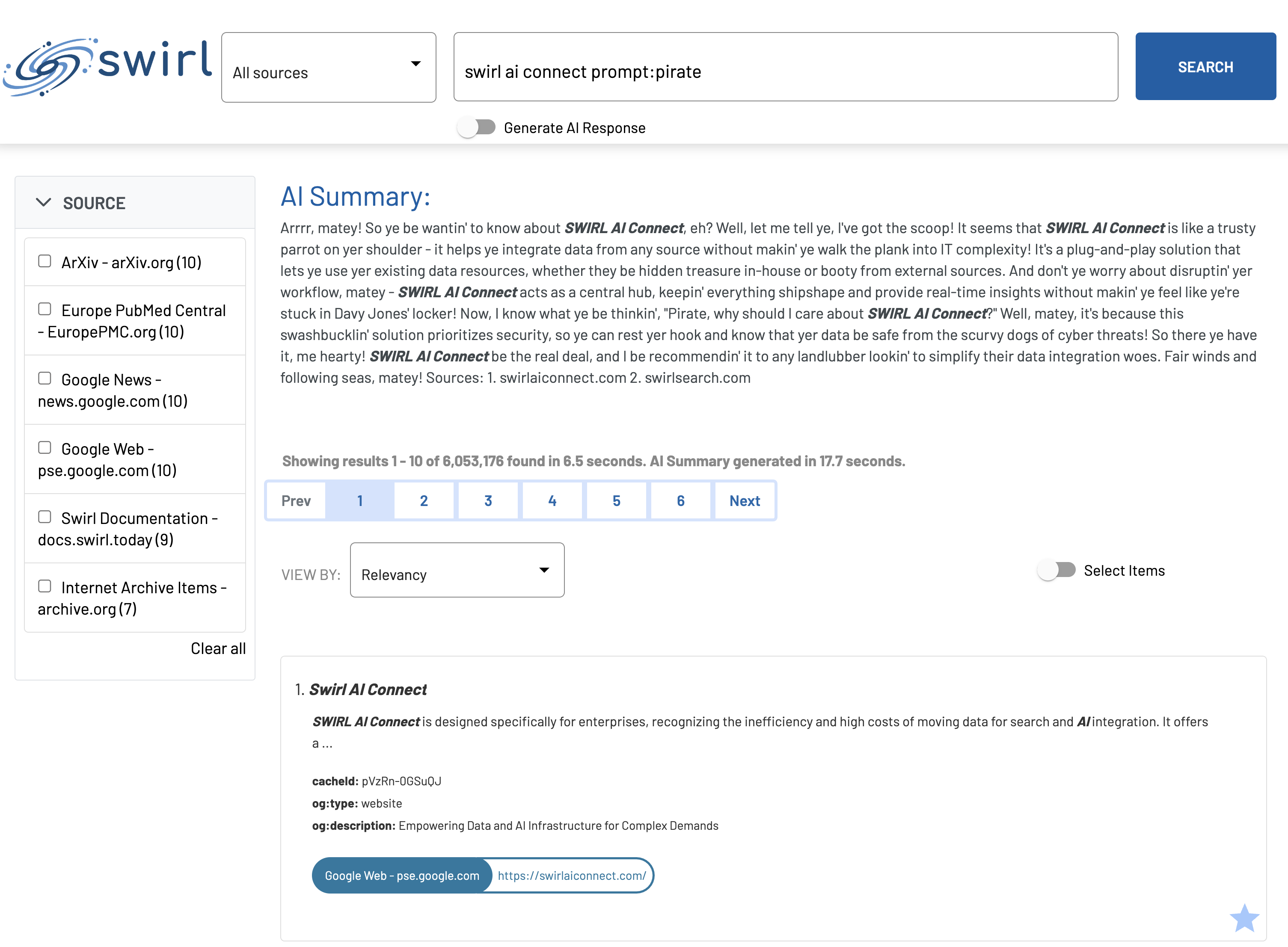
Using a Prompt in a Query Processor or Connector
To specify a prompt when using an LLM for query rewriting or direct question answering:
- Follow the steps in Connecting to Generative AI (GAI) and Large Language Models (LLMs).
- See the Developer Guide section on Using an LLM to Rewrite Queries.
Optimizing RAG
Using Summaries
Set SWIRL_ALWAYS_FALL_BACK_TO_SUMMARY to True to enable SWIRL to use result summaries for RAG. This is the best option for sources where full-page fetching is restricted due to authentication limitations.
Distribution Strategy
The distribution strategy determines how SWIRL selects pages from search results per source. Configure it by setting SWIRL_RAG_DISTRIBUTION_STRATEGY to one of:
Distributed— maintains the original sort order and evenly selects pages from each source. Example: if two sources return results, SWIRL selects five pages from each, adding them to the prompt until token limits are reached. The sort order remains unchanged, andswirl_scoreis not used.RoundRobin— selects pages in a round-robin fashion across sources. Respects each source's internal sort order but ignoresswirl_score.Sorted(default) — selects pages byswirl_score, using only results with aswirl_scoregreater than 50.
Model Maximum Pages and Tokens
- Set the RAG model — use
SWIRL_RAG_MODELto specify the LLM for RAG. - Limit the number of pages considered — configure
SWIRL_RAG_MAX_TO_CONSIDER. - Control token usage — use
SWIRL_RAG_TOK_MAXto set the maximum number of tokens in the prompt sent to the LLM.
Notes
- When adjusting
SWIRL_RAG_MODELorSWIRL_RAG_TOK_MAX, keep values within the model's token limit. - SWIRL uses model-specific encodings to count tokens but also respects user-defined limits.
- The default
SWIRL_RAG_TOK_MAXis set below the model's maximum to prevent excessive response latency.
Configuring the Authenticating Page Fetcher for RAG with Enterprise Content
SWIRL Enterprise includes a Page Fetcher that retrieves results from sources requiring authentication.
-
Search
Federate the query across every active SearchProvider in parallel.
-
Re-Rank
Normalise and re-score results across sources using cosine vector similarity.
-
Review
Optionally let the user inspect, sort, or trim the result set before generation.
-
Fetch
Pull full text from each chosen source in real time, using authorised credentials.
-
Read
Vectorise the fetched text and pick the passages most relevant to the query.
-
Prompt
Bind passages into a prompt and dispatch to the configured generative model.
-
Package
Return an AI-generated answer with inline citations linking back to each source.
The Page Fetcher authenticates using the user's token or a configured authentication method for each source.
The following sections explain how to configure Page Fetching for specific SearchProviders.
Google PSE SearchProviders
For public source data via Google PSE SearchProviders, the recommended configuration uses Diffbot — a page-fetching and content-cleaning service.
Configuration with Diffbot
"page_fetch_config_json": {
"cache": "false",
"fallback": "diffbot",
"diffbot": {
"token": "<Diffbot-API-Token-Here>",
"scholar.google.com": {
"extract_entity": "article"
}
},
"headers": {
"User-Agent": "Swirlbot/1.0 (+http://swirl.today)"
},
"www.businesswire.com": {
"timeout": 60
},
"www.linkedin.com": {
"timeout": 5
},
"rs.linkedin.com": {
"timeout": 5
},
"uk.linkedin.com": {
"timeout": 5
},
"au.linkedin.com": {
"timeout": 5
},
"timeout": 30
}
To obtain a Diffbot token, sign up at diffbot.com.
Configuration Without Diffbot
If you prefer not to use Diffbot, use the following configuration:
"page_fetch_config_json": {
"cache": "false",
"headers": {
"User-Agent": "Swirlbot/1.0 (+http://swirl.today)"
},
"www.businesswire.com": {
"timeout": 60
},
"www.linkedin.com": {
"timeout": 5
},
"rs.linkedin.com": {
"timeout": 5
},
"uk.linkedin.com": {
"timeout": 5
},
"au.linkedin.com": {
"timeout": 5
},
"timeout": 30
}
Note: For more details on configuring Google PSE SearchProviders, refer to the SearchProvider Guide.
Notes
cacheis set tofalseby default as of Release 3.0.fallback: "diffbot"enables automatic failover — SWIRL attempts normal fetching first, using Diffbot only if the initial fetch fails. This improves speed, since Diffbot requests are slower.headersdefine request headers sent with each page request.- Domain-specific
timeoutvalues serve two purposes: allowing slow but valuable sources (e.g.,www.businesswire.com) to return data, and enforcing quick failures for unsupported sites (e.g.,www.linkedin.com) so Diffbot can be used instead. - Diffbot requires a paid account with an associated API token.
M365 Configurations
Diffbot should not be used with Microsoft sources.
Note: The content_url field is a template URL that dynamically constructs a URL using search result data. SWIRL uses this URL to fetch actual content.
Microsoft Outlook Messages
Add the following configuration to the Microsoft Outlook Messages SearchProvider:
"page_fetch_config_json": {
"cache": "false",
"headers": {
"User-Agent": "Swirlbot/1.0 (+http://swirl.today)"
},
"timeout": 10
}
Microsoft Calendar
Add the following configuration to the Microsoft Calendar SearchProvider:
"page_fetch_config_json": {
"cache": "false",
"content_url": "https://graph.microsoft.com/v1.0/me/events/'{hitId}'",
"headers": {
"User-Agent": "Swirlbot/1.0 (+http://swirl.today)"
},
"timeout": 30
}
Microsoft OneDrive
Configuration Options
| Field | Description |
|---|---|
content_url |
The URL to fetch the page content if different from the URL mapped to SWIRL’s url field. |
mimetype_url |
The URL to fetch the mimetype of the content. |
mimetype_path |
JSON path to extract the mimetype from the fetched object. |
mimetype_whitelist |
List of mimetypes allowed for content fetching. |
OneDrive Configuration
- The configuration below enables fetching HTML, PDFs, and Microsoft Office documents.
- Binary content (PDF, DOCX, PPTX, etc.) requires a configured text extractor for RAG.
"page_fetch_config_json": {
"cache": "false",
"content_url": "https://graph.microsoft.com/v1.0/drives/'{resource.parentReference.driveId}'/items/'{resource.id}'/content",
"mimetype_url": "https://graph.microsoft.com/v1.0/drives/'{resource.parentReference.driveId}'/items/'{resource.id}'",
"mimetype_path": "'{file.mimeType}'",
"mimetype_whitelist": [
"application/pdf",
"application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"application/vnd.openxmlformats-officedocument.presentationml.presentation",
"image/png",
"text/html"
],
"headers": {
"User-Agent": "Swirlbot/1.0 (+http://swirl.today)"
},
"timeout": 30
}
Microsoft SharePoint
To fetch Sharepoint objects, add the following configuration to the Microsoft SharePoint SearchProvider:
"page_fetch_config_json": {
"cache": "false",
"content_url": "https://graph.microsoft.com/beta/sites/'{hitId}'/drives",
"headers": {
"User-Agent": "Swirlbot/1.0 (+http://swirl.today)"
},
"timeout": 10
}
This configuration lets SWIRL fetch authenticated content from Microsoft sources.
Customizing
SWIRL recommends using the RequestsPost connector for advanced querying. This section describes how to configure it.
Here is a sample SearchProvider:
{
"name": "Sharepoint Advanced Query",
"description": "Searches a set of documents. Supports most languages.",
"owner": "admin",
"shared": true,
"active": true,
"default": false,
"authenticator": "Microsoft",
"connector": "RequestsPost",
"url": "https://graph.microsoft.com/beta/search/microsoft.graph.query",
"query_template": "{url}",
"query_template_json": {},
"post_query_template": {
"requests": [
{
"from": 0,
"size": 10,
"query": {
"queryString": "( {query_string} ) AND site:\"https://<m365-tenant-name>.sharepoint.com/sites/<site-name>*\" AND (ContentTypeId:0x0101009D1CB255DA76424F860D91F20E6C411800FE9B4A881A37C14EB317C8BB00D7678E OR ContentTypeId:0x0101005F15B24C83D3604385BF439DD37F6A1D)"
},
"fields": [
"ContentTypeId",
"title",
"webUrl",
"lastModifiedDateTime",
"description"
],
"entityTypes": [
"driveItem",
"listItem"
]
}
]
},
"http_request_headers": {
"Content-Type": "application/json"
},
"page_fetch_config_json": {},
"query_processors": [
"NoModQueryProcessor"
],
"query_mappings": "NO_URL_ENCODE",
"result_grouping_field": "",
"result_processors": [
"MappingResultProcessor",
"CosineRelevancyResultProcessor"
],
"response_mappings": "FOUND=value[0].hitsContainers[0].total,RESULTS=value[0].hitsContainers[0].hits",
"result_mappings": "url=resource.webUrl,title='{$[*].resource..fields.title}',body='{summary} - {resource.fields.description}',date_published=resource.createdDateTime,author=resource.createdBy.user.displayName",
"results_per_query": 10,
"credentials": "",
"eval_credentials": "",
"tags": [
"sp1"
],
"ephemeral_store_config_json": {
"ephemeral": false
},
"query_language": "Generic_Keyword",
"config": {}
}
The SearchProvider above must be edited before use.
The SearchProvider above will not work without the quote-handling transformer installed. Follow the procedure under Quote Handling to install it.
query_processors
Specify NoModQueryProcessor in the query_processors list instead of AdaptiveQueryProcessor. This ensures the query is not modified in the SearchProvider.
post_query_template
The post_query_template field contains JSON that wraps additional query parameters.
- Change
<m365-tenant-name>and<sharepoint-site-name>to the appropriate values for your tenant. - The
query_stringis filled in at run time by SWIRL. The value is wrapped in parentheses because it may contain keywords likeAND,OR, orNOT, and may include nested parentheses. ContentTypeIdspecifies which types of documents to focus on. For SharePoint and OneDrive, the main types aredriveItemandlistItem.
Quote Handling
SWIRL Enterprise 4.2 and earlier requires a query transformer to handle quoted searches in SharePoint correctly.
To install this transformer:
- Download the file.
- Log in to the SWIRL admin's query-transform CSV page at http://localhost/api/swirl/query_transform_form/.

- Enter the name
escape_quotes. - Leave the type set to
Rewrite. - Click
Choose file, select the downloaded CSV, then clickUpload(highlighted in green above).
The file uploads and redirects you back to the homepage.
Contact support if you receive an error message.
Extracting Enterprise Content with Apache Tika
SWIRL integrates Apache Tika to extract text from various file types. The following sections explain how to deploy and configure it.
Running Apache Tika
For local installations, start Tika using Docker:
docker run -d -p 9998:9998 apache/tika
To use a remote Tika instance, set TIKA_SERVER_ENDPOINT in SWIRL’s .env file:
TIKA_SERVER_ENDPOINT='http://<your-tika-server>:9998/'
Restart SWIRL after making changes.
SearchProvider Configuration
Refer to the Microsoft OneDrive section for a Page Fetcher configuration that integrates Tika for extracting text from PDFs, Microsoft Office documents, and other file formats retrieved via the Microsoft Graph API.
To support additional file types, expand the whitelist to include any document format that Tika supports.
Configuring Passage Detection with Reader LLM
SWIRL Enterprise includes passage detection in the Reader LLM, which improves RAG accuracy by identifying relevant sections of text.
Running passage detection locally
Start the passage detection service using Docker:
docker run -p 7029:7029 -e SWIRL_TEXT_SERVICE_PORT=7029 swirlai/swirl-integrations:topic-text-matcher
Configuration Options
The following environment variables allow customization of Reader LLM and RAG settings:
| Variable | Description | Example |
|---|---|---|
SWIRL_TEXT_SUMMARIZATION_URL |
URL where the passage detection service is running | http://localhost:7029/ |
SWIRL_TEXT_SUMMARIZATION_TIMEOUT |
Maximum response wait time for RAG | 60s |
SWIRL_TEXT_SUMMARIZATION_MAX_SIZE |
Maximum text block size sent for summarization | 4K |
SWIRL_TEXT_SUMMARIZATION_TRUNCATION |
If true, only text containing summarization tags is included in the RAG prompt |
true |
SWIRL_RAG_MODEL |
ChatGPT model identifier used for RAG | "gpt-4" |
SWIRL_RAG_TOK_MAX |
Maximum number of tokens sent to ChatGPT | 4000 |
SWIRL_RAG_MAX_TO_CONSIDER |
Maximum search results considered for RAG | 10 |
SWIRL_RAG_DISTRIBUTION_STRATEGY |
Defines how search results are selected for RAG: Distributed, RoundRobin, or Sorted |
RoundRobin |
About SWIRL_RAG_DISTRIBUTION_STRATEGY
If set to Distributed, and the number of documents is less than SWIRL_RAG_MAX_TO_CONSIDER, SWIRL backfills results by iterating through the next available results.
Example .env Configuration
SWIRL_TEXT_SUMMARIZATION_URL='http://localhost:7029/'
SWIRL_TEXT_SUMMARIZATION_TRUNCATION=True
SWIRL_RAG_DISTRIBUTION_STRATEGY='RoundRobin'
TIKA_SERVER_ENDPOINT='http://localhost:9998/'
This configuration ensures Apache Tika and Reader LLM passage detection are correctly integrated into SWIRL AI Search.
Text Summarization
When SWIRL_TEXT_SUMMARIZATION_URL is set to a Text Analyzer URL, SWIRL sends text to the Text Analyzer before further RAG processing. This lets SWIRL tag the parts of the text most relevant to the query before they are included in the LLM prompt.
Example: Tagged Text in a Prompt
--- Content Details ---
Type: Web Page
Domain: swirl.today
Query Terms: 'Swirl'
Important: Text between <SW-IMPORTANT> and </SW-IMPORTANT> is most pertinent to the query.
--- Content ---
<SW-IMPORTANT>WHO IS SWIRL? </SW-IMPORTANT>
<SW-IMPORTANT>Getting to know Swirl Swirl is a powerful solution for identifying and using information. </SW-IMPORTANT>
<SW-IMPORTANT>Swirl was launched in 2022 and operates under the Apache 2.0 license. </SW-IMPORTANT>
<SW-IMPORTANT>At Swirl we follow an iterative approach to software development adhering to the principles of agile methodology. </SW-IMPORTANT>
We believe in delivering high-quality releases through each stage of our development lifecycle.
Text Truncation
When text truncation is enabled, only text that contains at least one important tagged section (as shown above) is included in the LLM prompt.
Enabling text truncation
To activate this feature, both conditions must be met:
SWIRL_TEXT_SUMMARIZATION_URLis set to a valid Text Analyzer URL.SWIRL_TEXT_SUMMARIZATION_TRUNCATIONis set totrue.
Log Entries for Truncated Content
When a text chunk is excluded due to summarization truncation, logs will show entries like this:
2023-10-19 09:34:01,828 INFO RAG: url:https://www.wendoverart.com/wtfh0301 problem:RAG Chunk not added for 'Swirl' : SUMMARIZATION TRUNCATION
This ensures only the most relevant content is included in RAG.
PII Detection and Removal
SWIRL Enterprise supports automatic PII (Personally Identifiable Information) detection and removal using Microsoft Presidio. When enabled, PII entities are detected in search results and redacted before being returned to the user.
Supported entity types
Presidio detects a wide range of PII entities, including names, email addresses, phone numbers, credit card numbers, social security numbers, and more.
Configuration:
- Install the Presidio dependencies:
pip install -r requirements-presidio.txt
-
Add
RemovePIIResultProcessorto theresult_processorslist in the relevant SearchProvider configuration. -
Restart SWIRL for changes to take effect.
PII detection adds processing overhead. Test performance impact before enabling in production on high-volume SearchProviders.
Multi-Language Support
SWIRL supports multiple languages for query processing and relevancy ranking through configurable spaCy models.
Configured Languages:
| Language | spaCy Model | Setting |
|---|---|---|
| English | en_core_web_lg |
SWIRL_SPACY_MODEL_EN |
| German | de_core_news_lg |
SWIRL_SPACY_MODEL_DE |
| Japanese | ja_core_news_lg |
SWIRL_SPACY_MODEL_JA |
| PII Detection | en_core_web_sm |
SWIRL_SPACY_MODEL_PII |
Related Settings:
| Setting | Default | Description |
|---|---|---|
SWIRL_DEFAULT_LANGUAGE |
en |
Default language code |
SWIRL_DEFAULT_QUERY_LANGUAGE |
english |
Stopword dictionary language |
SWIRL_PROMPT_LANGUAGE |
en |
Language for AI prompt templates |
Adding a New Language:
- Install the appropriate spaCy model:
python -m spacy download <model-name> - Add a
SWIRL_SPACY_MODEL_<LANG>setting insettings.pyor.env - Restart SWIRL
Performance Optimization:
SWIRL_SPACY_VECTORS_FP16(default:True) — Uses half-precision vectors to reduce memory usageSWIRL_SPACY_USE_EMBEDDINGS_CACHE(default:True, max size: 2000) — Caches computed embeddings for repeated terms